Quantitative Evaluations
1. Final Layer Evaluation
We follow CLIP-Dissect [1] to quantitatively
analyze description quality on the last layer neurons, which
have known ground truth labels (i.e. class name) to allow
us to evaluate the quality of neuron descriptions automatically.
Our results show that DnD outperforms MILAN [2], having a
greater average CLIP cosine similarity by 0.0518, a greater
average mpnet cosine similarity by 0.18, and a greater average
BERTScore by 0.008.
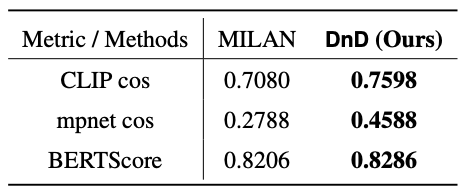
Textual similarity between DnD/MILAN labels and ground truths on ResNet-50 (Imagenet).
We can see DnD outperforms MILAN.
2. MILANNOTATIONS
We also performed quantitative evaluation by calculating the textual similarity between a method's label
and the corresponding MILANNOTATIONS. Our analysis found that
if every neuron is described with the same constant concept:
'depictions', it will achieve better results than any
explanation method on this dataset, but this is not a useful
nor meaningful description. Thus, the dataset is unreliable to serve as ground
truths and can't be relied on for comparing different methods.
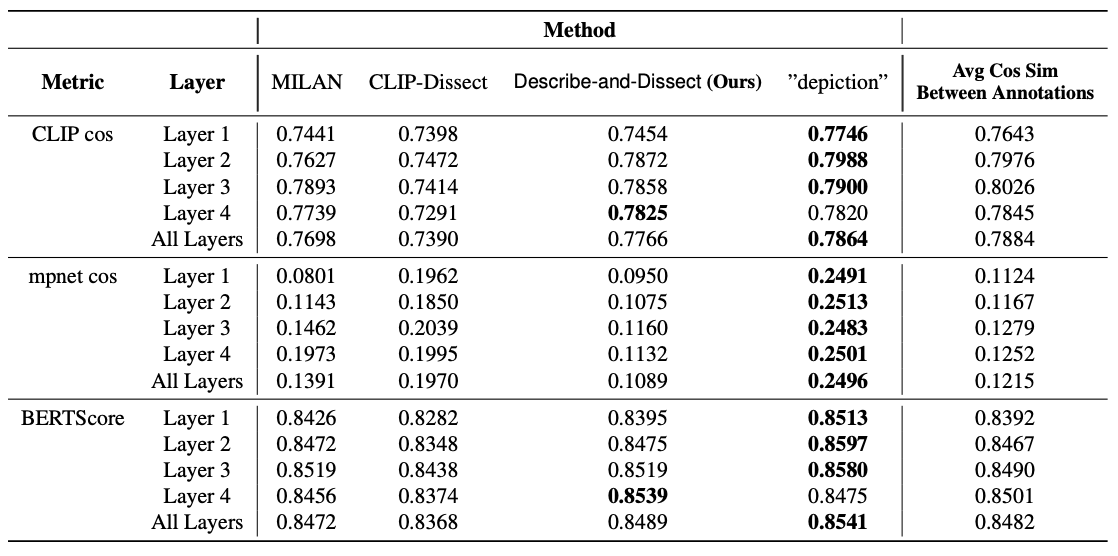
Textual similarity between descriptions produced by methods and MILANNOTATIONS.
Simply labeling every neuron as ”depictions” outperforms all other methods, demonstrating the unreliability
of MILANNOTATIONS as an evaluation method.
3. Crowdsourced Experiment
Our experiment compares the quality of labels produced by DnD against 3
baselines: CLIP-Dissect, MILAN, and Network Dissection [3]. For both models we evaluated
4 of the intermediate layers (end of each residual block),
with 200 randomly chosen neurons per layer for ResNet50
and 50 per layer for ResNet-18. Each neurons description is evaluated by 3 different workers.
We outline specifics of the experiment below:
- Workers are presented with the top 10 highest activating images of a neuron.
- Four separate descriptions are given, each corresponding to a label produced by one of the four methods compared.
- Workers select the description that best represents the 10 highly activating images presented.
- Descriptions are rated on a 1-5 scale. A rating of 1 represents that the user "strongly disagrees" with the
given description, and a rating of 5 represents that the user "strongly agrees" with the given description.
Our results show that DnD performs over 2× better than all baseline methods when dissecting ResNet-50
and over 3× better when dissecting ResNet18, being selected the best of the three an impressive 63.21%
of the time.

Results for individual layers of ResNet-50.
We observe that DnD is the best method across all layers in ResNet-50.
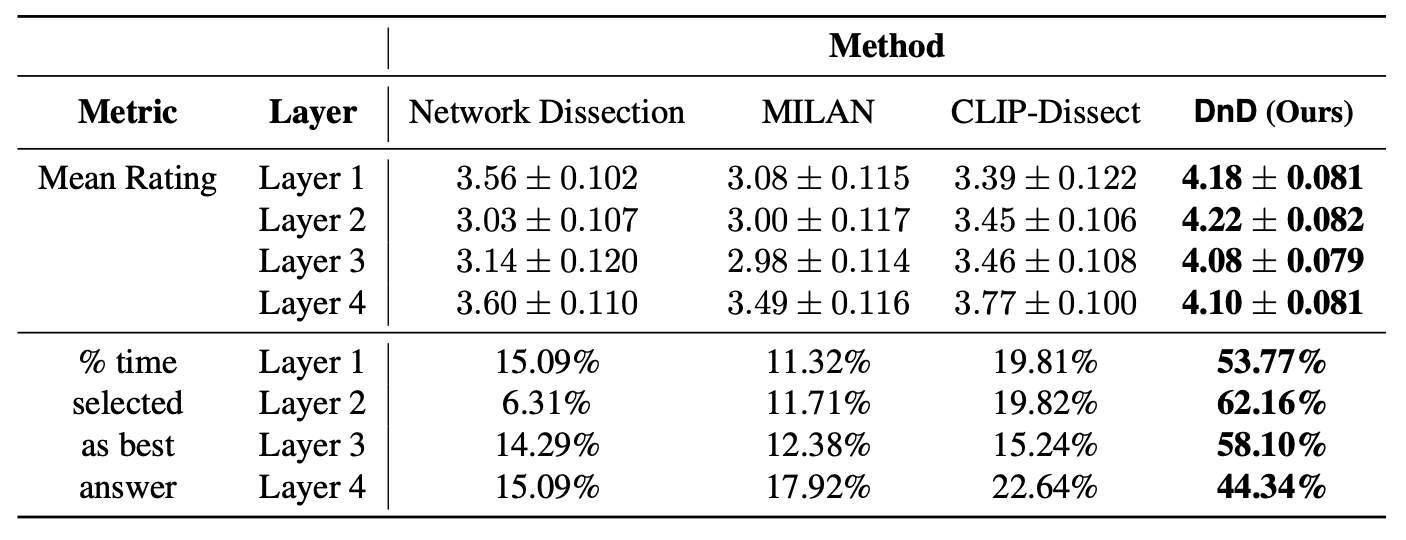
Results for individual layers of ResNet-18.
DnD performs significatly better across every layer in ResNet-18 when compared
to the baseline methods
4. Use Case
To showcase a potential use case for neuron descriptions,
we experimented with using neuron descriptions to find a good classifier for a class missing from
the training set. We use neurons from Layer 4 of ResNet-50 (Imagenet) to find neurons in this layer that
could serve as the best classifiers for an unseen class, specifically the classes in CIFAR-10 and CIFAR-100 datasets.
Our setup is as follows:
- Explain all neurons in Layer 4 of ResNet-50 (ImageNet) using different methods.
- Find the neuron whose description is closest to the CIFAR class name in a text embedding space
(ensemble of the CLIP ViT-B/16 and mpnet text encoders)
- Measure the average activation to determine how well the neuron performs as a single class class
classifier on the CIFAR validation dataset, measured by area under ROC curve.

The average classification AUC on out of distribution
dataset when using neurons with similar description as a classifier.
We can see that our DnD clearly outperforms MILAN, the only
other generative description method.
5. Ablation Studies
For further insight, we conduct comprehensive ablation studies analyzing the importance of each step in the DnD pipeline.
We perform the following experiments with additional details shown here:
- Attention Cropping Ablation (Step 1)
- Image Captioning with Fixed Concept Sets (Step 2)
- Image-to-Text Model Ablation (Step 2)
- Effects of GPT Summarization (Step 2)
- Effects of Concept Selection (Step 3)

