Describe-and-Dissect: Interpreting Neurons in Vision Networks with Language Models
Ablation Studies
We conduct comprehensive ablation studies analyzing the importance of each step in the DnD pipeline. We outline our experiments below:
1. Attention Cropping Ablation (Step 1)
Image captioning models are prone to spuriously
correlated concepts which are largely irrelevant to a neuron’s activation. To determine the effects of attention cropping on
subsequent processes in the DnD pipeline, we evaluate DnD on without augmented image crops.
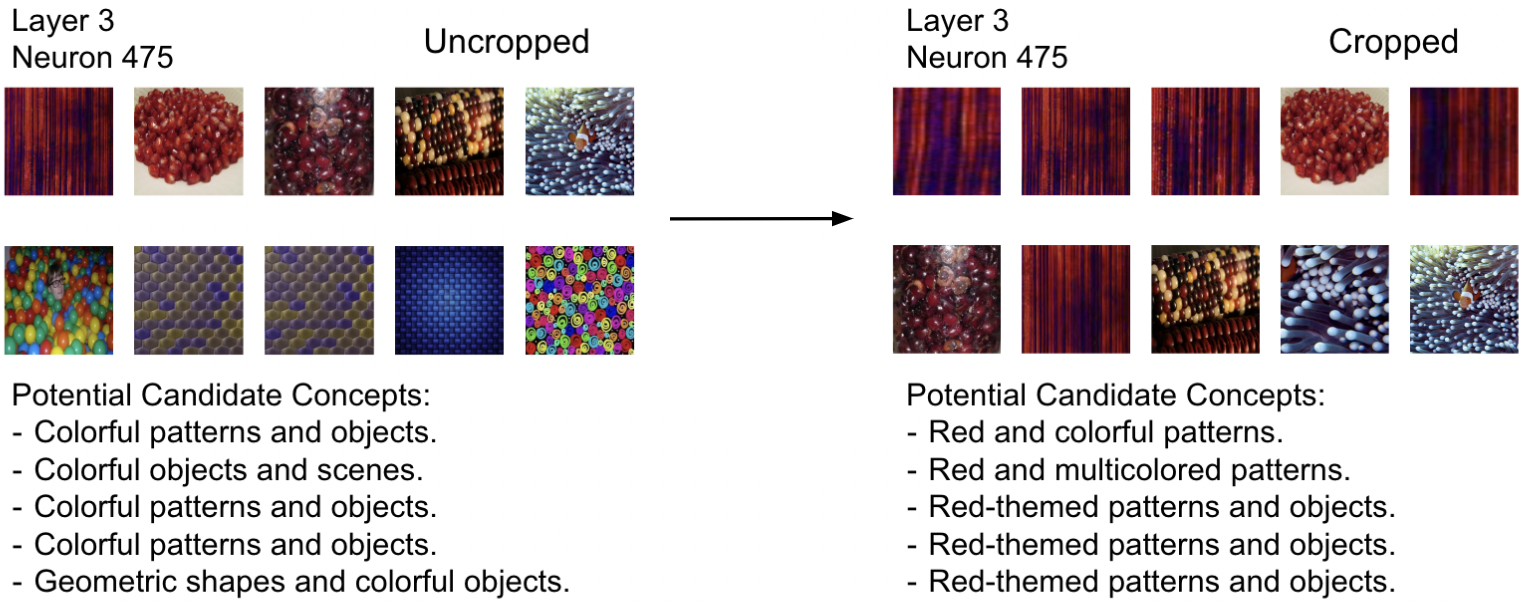
Difference between using augmented probing dataset (right) and non-augmented probing dataset (left) on Layer 3 Neuron 475 Candidate Concepts. We see that Attention Cropping eliminates spuriously correlated connections.
2. Image Captioning with Fixed Concept Sets (Step 2)
To analyze the importance of using a generative image-to-text model, we explore utilizing fixed concept sets with
CLIP to generate descriptions for each image instead of BLIP, keeping the remaining pipeline the same.
We use our model to describe the final layer neurons of
ResNet-50 and compare descriptions similarity to the class name that neuron is
detecting. In intermediate layers, we notice that single word concept captions significantly limit the expressiveness of DnD
and that having generative image descriptions is important for our overall performance.

Examples of DnD with CLIP Image Captioning Compared to DnD (with BLIP). Despite producing similar results on the FC layer, we see that DnD (with BLIP) outperforms DnD with CLIP image captioning, especially on intermediate layer neurons.

Mean FC Layer Similarity of CLIP Captioning. With CLIP cosine similarity, mpnet cosine similarity, and BERTScore, we find the performance of DnD w/ CLIP Captioning is slightly worse than BLIP generative caption.
We also note failure cases for CLIP Image Captioning shown below.

Failure Cases of CLIP Image Captioning. Due to the lack of expressiveness of static concept sets, GPT summarization fails to identify conceptual similarities within CLIP image captions.
3. Image-to-Text Model Ablation (Step 2)
In light of advancements in image-to-text models, we compare BLIP to a more recently released model, BLIP-2. We experiment with using BLIP-2 as the image-to-text model and quantitatively compare with BLIP by computing the mean cosine similarity between the best concept chosen from Concept Selection. We find that BLIP and BLIP-2 produce highly correlated concepts across all four layers of RN50 and a 87.0% similarity across the entire network.
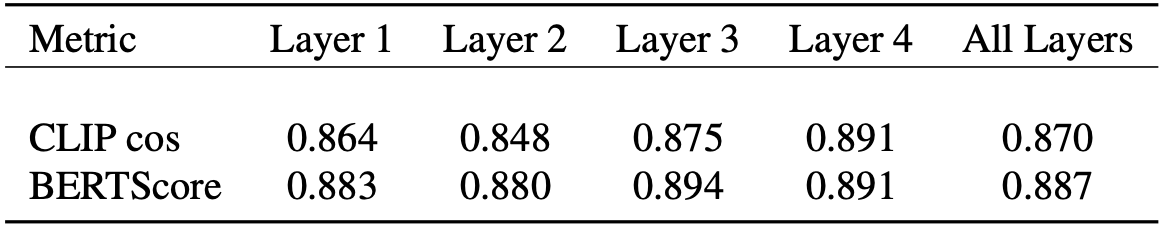
Mean Cosine Similarity Between BLIP and BLIP-2 Labels. Similar conceptual ideas between both models are reflected in the high similarity scores.
However, we note specific situations where BLIP-2 fails to identify low-level concepts BLIP is able to capture.

Examples of BLIP-2 failure cases. BLIP-2 overlooks crucial low level concepts in early layers of RN50.
4. Effects of GPT Summarization (Step 2)
DnD utilizes OpenAI’s GPT-3.5 Turbo to summarize similarities between the image caption generated for each K highly activating images of neuron n. Ablating away GPT, we substitute the summarized candidate concept set T with the image captions directly generated by BLIP for the K activating images of neuron n. We note two primary drawbacks:
- Poor Concept Quality. A failure case for both BLIP and BLIP-2 is the repetition of nonsensical elements within image captions. Processing these captions are computationally inefficient and can substantially extend runtime.
- Concept specific to a single image. Without the summarization step, concepts only describe a single image and fail to capture the shared concept across images.

Failure Cases in GPT-Ablation Study. Figure (a) demonstrates an example of poor concept quality and Figure (b) shows a failure case where the omission of concept summarization causes individual image captions to generalize to the entire neuron.
5. Effects of Concept Selection (Step 3)
We conducted an ablation study to determine the effectiveness of our Best Concept Selection (step 3) on the pipeline. DnD performance is already high without Best Concept Selection, but Concept Selection further improves the quality of selected labels Layers 2 through Layer 4, while having the same performance on Layer 1. Individual examples of the improvement Concept Selection are also shown below, with the new labels yielding more specific and accurate descriptions of the neuron.

Human evaluation results for DnD (w/o Best Concept Selection) versus full Describe-and-Dissect. Full pipeline improves or maintains performance on every layer in ResNet-50.
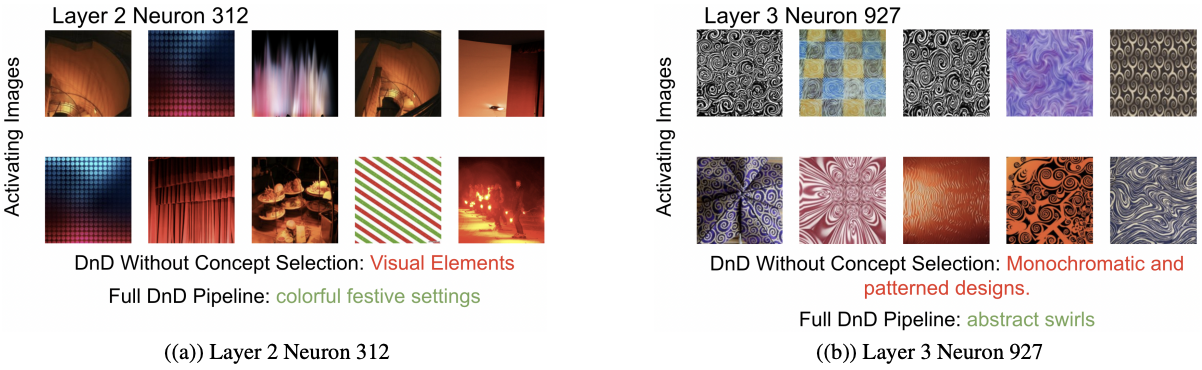
Concept Selection (Step 3) supplements Concept Generation (Step 2) accuracy. We show that concept selection improves Concept Generation by removing vague and spuriously correlated concepts.