CI-CBM — Ablation studies
Performance impact of different components of CI-CBM
We ablate the two mechanisms that stabilize past knowledge during class-incremental learning: pseudo-concept generation (geometry-aware synthetic concepts that separate old classes from new ones in concept space) and concept regularization (distillation that limits drift of units tied to earlier concepts).
Table 5 reports average incremental accuracy on CIFAR-100 and TinyImageNet for all four on/off combinations. Removing pseudo-concepts causes weights for previous classes to collapse toward zero, which wipes their accuracy and dominates the aggregate metric. Turning on concept regularization alone does not fix that collapse: regularization preserves bottleneck semantics but does not stop the classifier from ignoring old classes. Pseudo-concepts restore separation between old and new phases; adding regularization on top yields the best numbers, matching the full CI-CBM model.

Table 5. Experiment VI (ablation study). Performance impact of different components of CI-CBM.
Alternative concept generation methods
CI-CBM builds each phase’s concept vocabulary from language: we compare using GPT-3 prompts (default) against harvesting concepts from ConceptNet, a lexical knowledge graph rather than an LM. ConceptNet is cheaper and works reasonably on CIFAR-100 and TinyImageNet but lags GPT-3 by about two accuracy points. On CUB, ConceptNet-derived concepts fail almost entirely, whereas GPT-3 produces attributes that track fine-grained bird parts. This supports using a language model when concepts must capture subtle visual semantics.

Table A.4. Experiment X (ablation study). ConceptNet vs. GPT-3 for initial concept set generation.
Impact of sparsity on model performance
Following sparse linear bottleneck ideas (e.g., SAGA-style sparse predictors), CI-CBM encourages each class to activate only a small subset of concepts. Setting the sparsity coefficient λ to zero yields a dense final layer. As Table A.5 shows, dense training is slightly weaker than the sparse default on both benchmarks: a dense layer can overweight many pseudo-concept dimensions at once, whereas sparsity forces each class to commit to a compact concept signature and improves robustness across phases. Reported sparsity percentages confirm only a few percent of weights are active per configuration.

Table A.5. Experiment XI (ablation study). Performance impact of sparsity constraints.
Beyond accuracy, we repeat the Sturgeon concept-attribution visualization from the main paper while training the predictor without sparsity. The model still classifies correctly, but contributions spread across many concepts: no small set dominates, so explanations become long-winded and harder to audit.
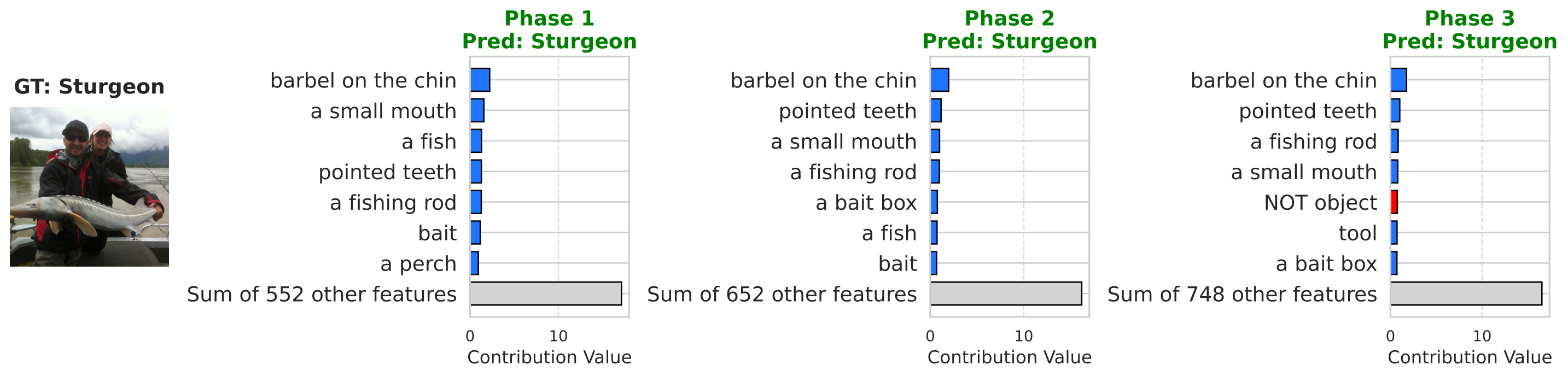
Figure A.1. Dense prediction layer (λ = 0): concept contributions for the same Sturgeon example as in the main paper (contributions spread across many concepts).
Effect of concept set size on performance
Real supervision may omit concepts. We randomly mask fractions of the vocabulary during training and record average incremental accuracy at 100%, 75%, 50%, and 25% concept availability (Table A.6). Accuracy drops slowly—under 3.5 points on CIFAR-100 and about two points on TinyImageNet even at 25%—showing that CI-CBM tolerates incomplete concept lists.

Table A.6. Experiment XII (ablation study). Accuracy vs. concept availability.
Qualitatively, we revisit Tree Swallow weights on CUB and Sturgeon attributions on ImageNet-Subset under 50% masking. When iconic attributes disappear from the pool, the network substitutes visually related concepts yet preserves coherent positive/negative structure across phases (Figures A.2–A.3).
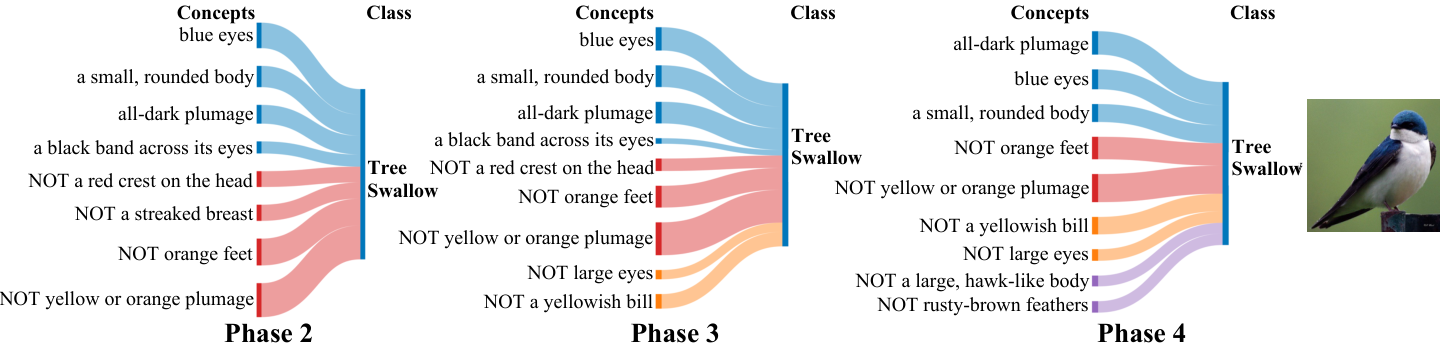
Figure A.2. Tree Swallow on CUB (four phases): final-layer weights with 50% of concepts randomly masked.
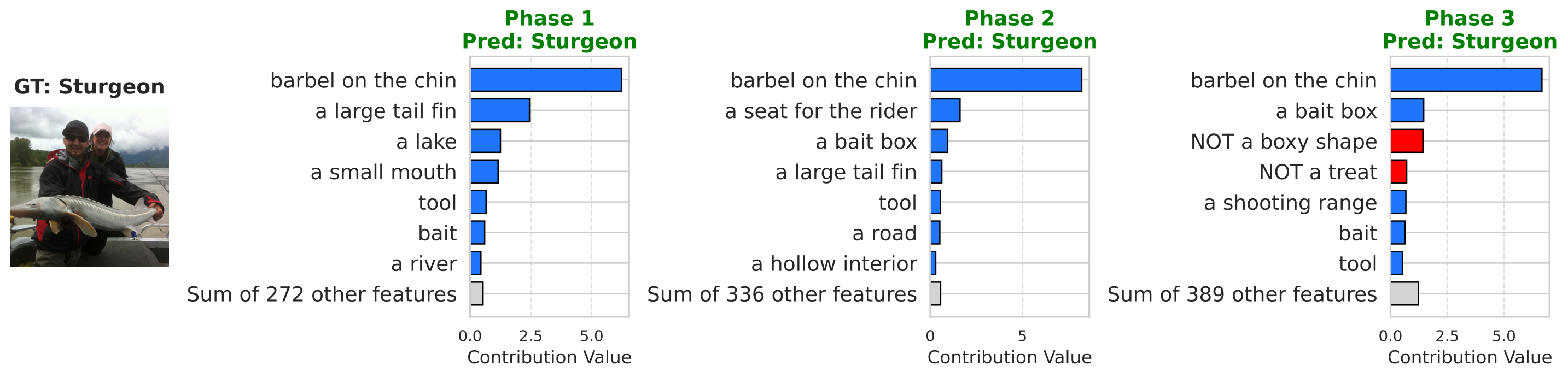
Figure A.3. Sturgeon on ImageNet-Subset: concept contributions with 50% concept masking.
Robustness to noise in image–concept alignment
The supervision matrix P aligns images with text concepts via a vision–language model; misalignment or estimator noise is unavoidable. We inject Gaussian noise into P at several SNRs during training. Table A.7 shows accuracy barely moves between clean activations and strongly corrupted ones, signalling that optimization does not hinge on perfectly crisp concept targets.

Table A.7. Experiment XIII (ablation study). Accuracy vs. SNR in image–concept alignment.
Alternative approach for learning the prediction layer
CI-CBM learns a shared linear predictor with pseudo-features mimicking old-class statistics in backbone space. We compare against two variants: local class discrimination, which expands the predictor but freezes weights for earlier classes (good when each phase introduces many classes, brittle when T is large because phases overlap); and concept-space prototype generation, which translates class centroids directly in concept coordinates. Prototype translation fails once the bottleneck expands and drifts—old centroids no longer live in the updated basis. Table A.8 shows both baselines decay sharply as T grows, whereas CI-CBM stays near its default accuracy.

Table A.8. Experiment XIV (ablation study). Performance comparison of alternative prediction-layer learning strategies.
Unique concept expansion
Each phase could append every GPT-generated string, but duplicates inflate the bottleneck and fragment attributions across synonymous units. CI-CBM filters so only genuinely new concepts enter the vocabulary. Compared with naïvely cumulative expansion, unique expansion roughly halves the number of active concepts by the final phase for T = 20, shrinking both matrices and making explanations shorter and more stable.
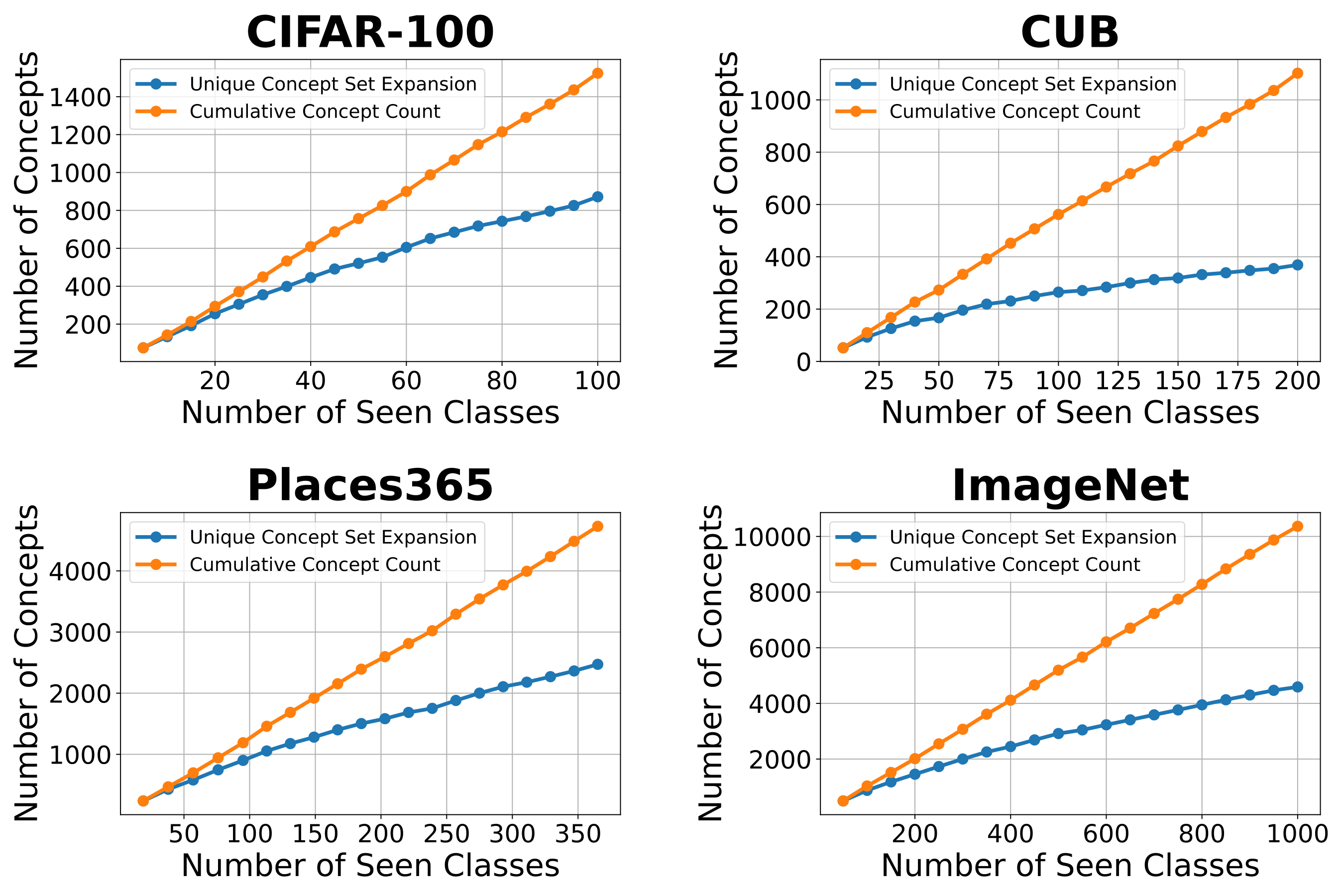
Figure A.4. Experiment XVI (ablation study). Concepts per number of seen classes (unique concept-set expansion vs. cumulative count).
Impact of distillation regularizer weight on accuracy
Distillation weight β trades off fidelity to previous concept activations versus fitting new data (same protocols as Experiments I–II depending on dataset). Removing distillation (β = 0) clearly hurts; large β overdamps adaptation. Performance peaks near β = 1, which is why all main experiments adopt that default (Table A.10).
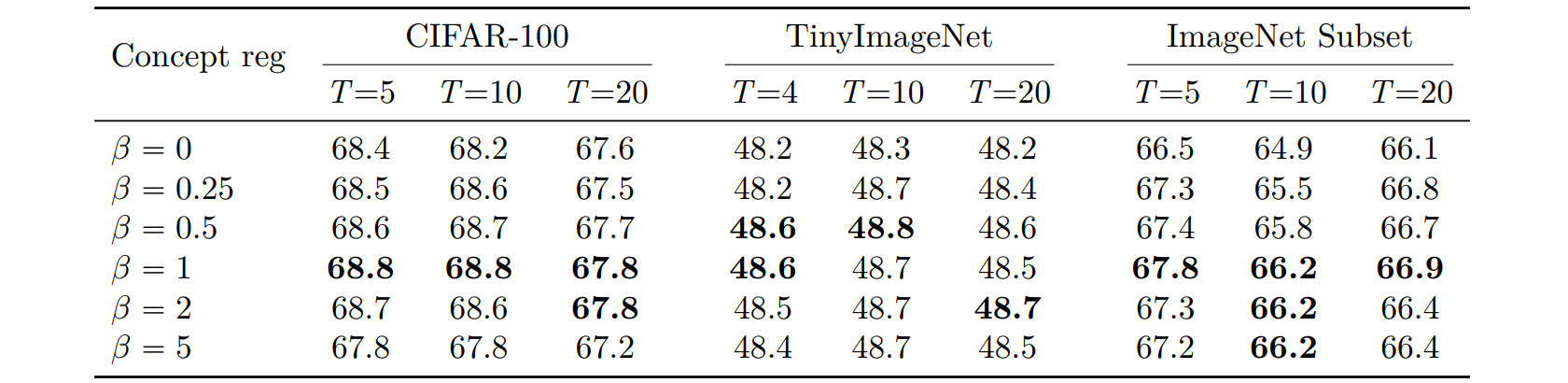
Table A.10. Experiment XVII (ablation). Effect of distillation weight β on average incremental accuracy.
Impact of the distillation regularizer on concept fidelity
Accuracy alone does not guarantee interpretable units. We therefore score how well each bottleneck neuron tracks its assigned concept text after continual training.
- CLIP cosine similarity. For every neuron we collect activations on the test split and compare that vector to each concept’s column of the CLIP-derived matrix P. We assign the best-matching concept and measure cosine similarity between the neuron’s activation profile and that concept’s profile in CLIP text–embedding space. Higher values mean the neuron fires like its semantic label predicts.
- Top-5 concept accuracy. Using the same ranking, we check whether the ground-truth concept text appears among the five nearest concepts by cosine similarity. This captures partial aliasing when synonyms appear in the vocabulary.
Enabling distillation-based concept regularization consistently raises both metrics across datasets and phase granularities (Table A.11), indicating that the regularizer fights representation drift without sacrificing the semantics attached to each bottleneck dimension.

Table A.11. Experiment XVIII (ablation study). Impact of distillation-based concept regularization on concept fidelity (CLIP cosine similarity and top-5 concept accuracy).
Impact of vision–language model (SigLIP vs CLIP)
Matrix P can be built with any aligned VLM. Keeping training identical to Experiment I, we swap CLIP for SigLIP. Table A.12 shows SigLIP yields higher average incremental accuracy on CIFAR-100, CUB, and TinyImageNet, suggesting sharper image–text alignment propagates into better pseudo-supervision.

Table A.12. Experiment XIX (ablation study). Incremental accuracy when computing concept activations P with CLIP vs. SigLIP.
Table A.13 repeats the fidelity evaluation from the previous section: SigLIP-tuned models achieve higher CLIP cosine similarity and top-5 concept accuracy, so bottleneck units stay better anchored to language even after many incremental phases.

Table A.13. Experiment XX (ablation study). Concept-fidelity metrics when computing P with CLIP vs. SigLIP.
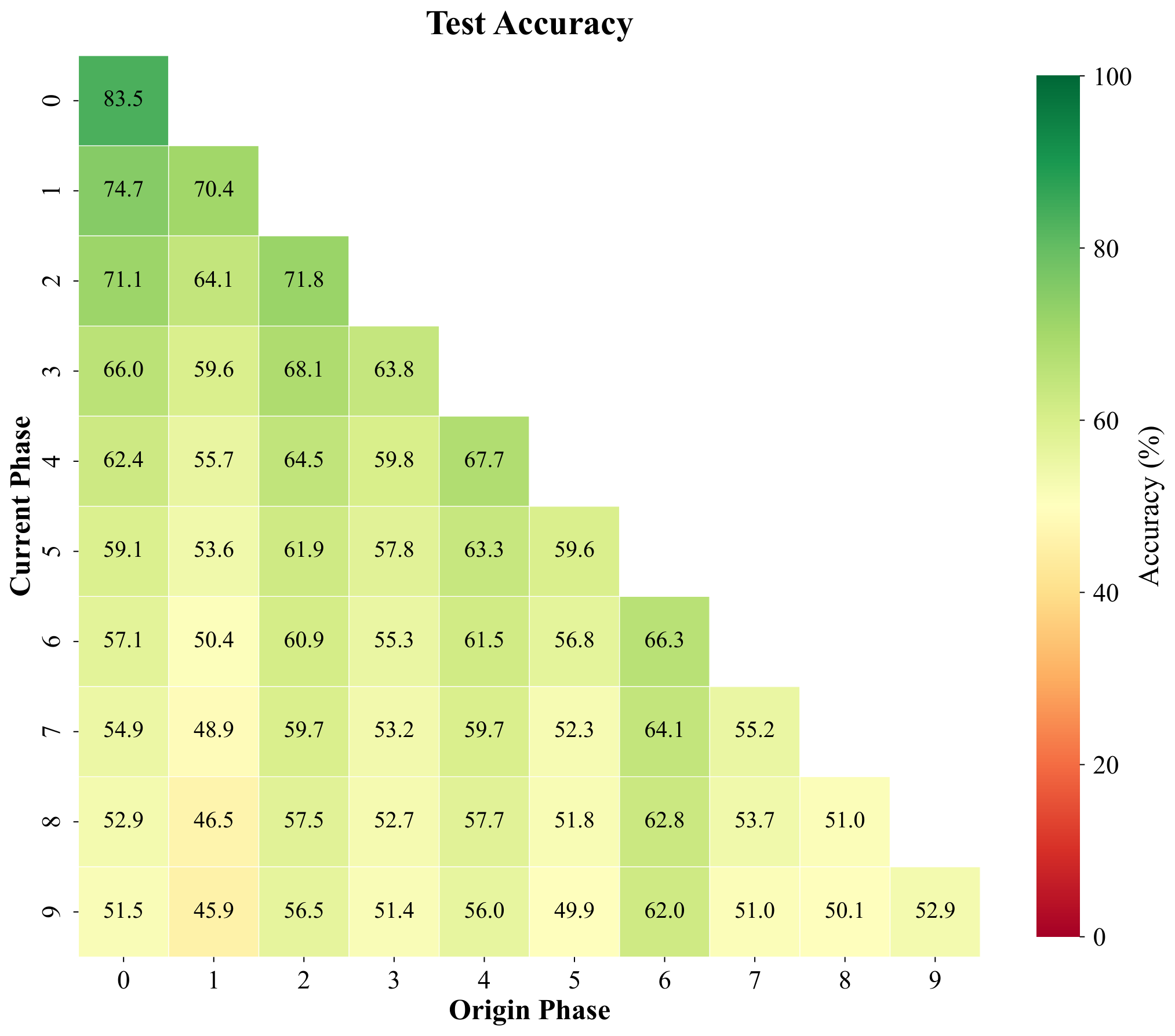
Pseudo-features track real feature geometry under a prototype classifier
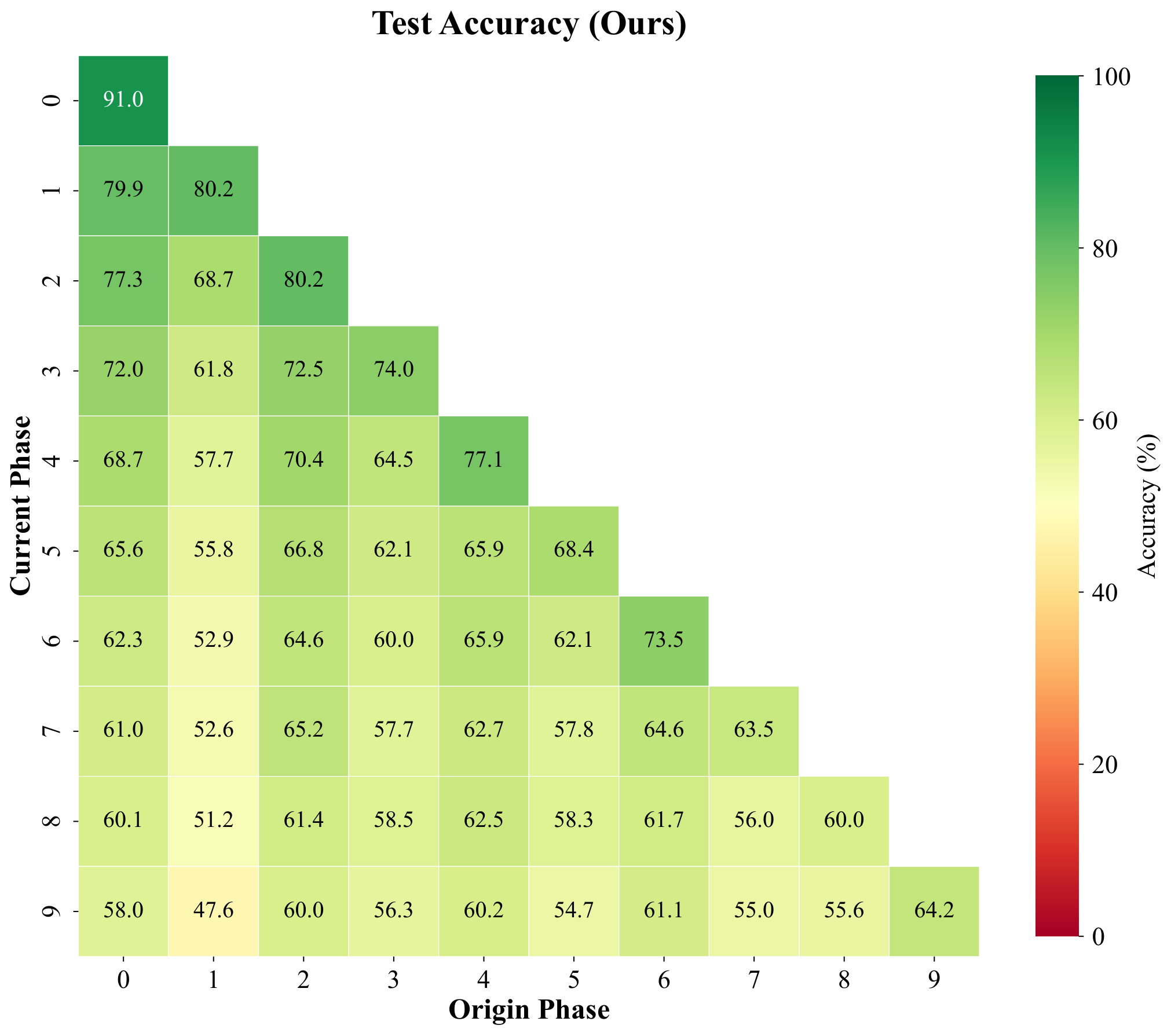
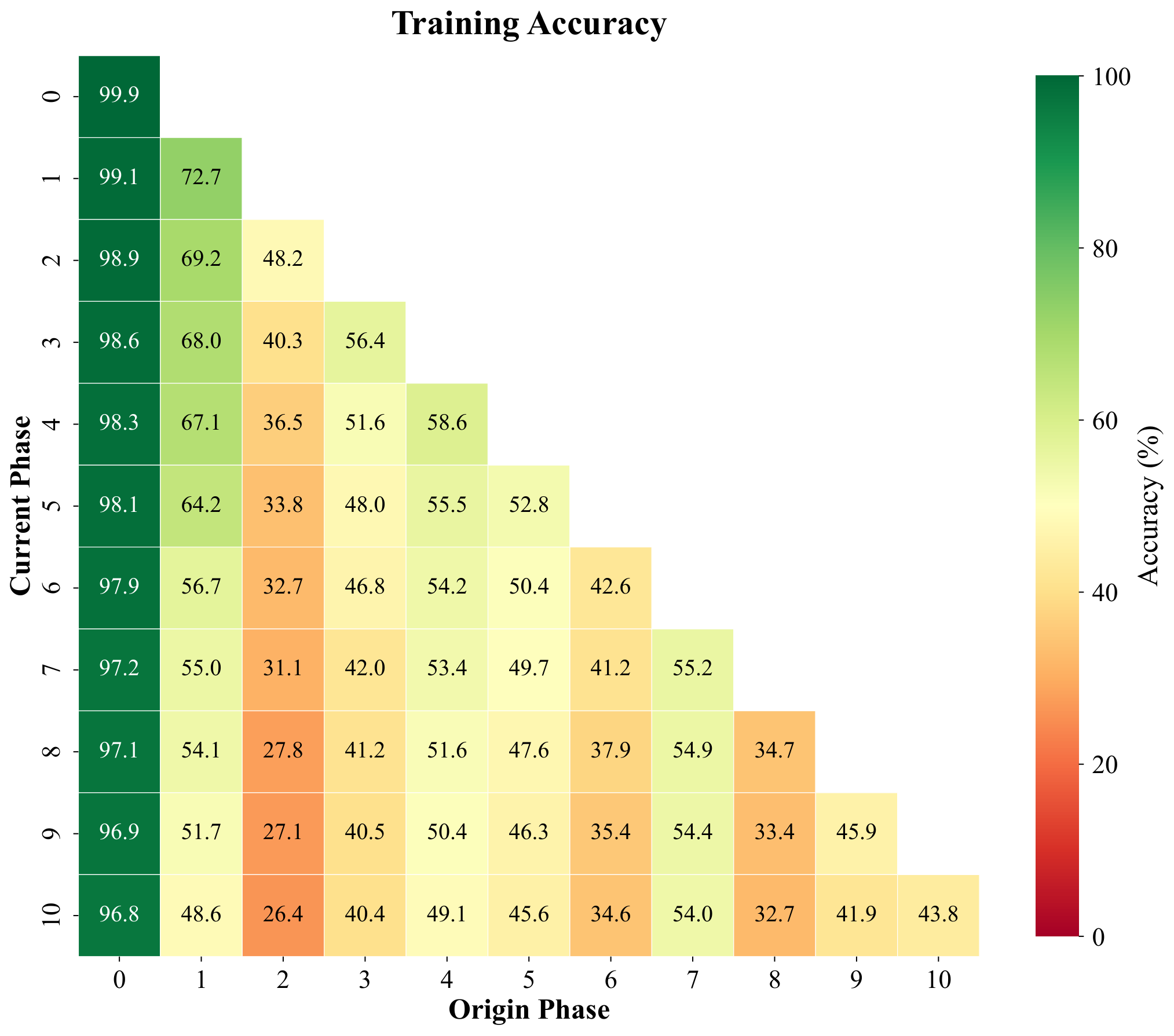
Pseudo-features are meant to mimic true backbone embeddings of forgotten classes. To test whether they behave like real data under a simple decision rule, we freeze features, build cosine prototypes per class from training samples, and compare four phase-by-phase matrices with entries (i, j): accuracy on classes introduced in phase j after training through phase i. The panels are (1) real training features under cosine prototypes, (2) pseudo-features under the same prototypes, (3) held-out real validation features, and (4) test accuracy of the full CI-CBM model (not the prototype classifier). We repeat for ImageNet-pretrained ResNet-18 (top row, T = 10 phases) and for a backbone trained only on first-phase data (bottom row, T = 11 phases), with the fourth column contrasting ImageNet-pretrained vs FeTrIL-style backbone heatmaps.
Pseudo-feature matrices closely track their training and validation counterparts: nearest-centroid confusion patterns stay aligned, which supports using pseudo samples as surrogates. Gaps still appear for classes introduced late when the backbone never saw them during pretraining—those limits show up for real embeddings too, so they reflect representation quality rather than a flaw exclusive to pseudo-features. Overall CI-CBM improves end-to-end test accuracy beyond what raw cosine prototypes achieve, especially when the backbone is weak.
Row 1 — ImageNet-pretrained ResNet-18 (T = 10)
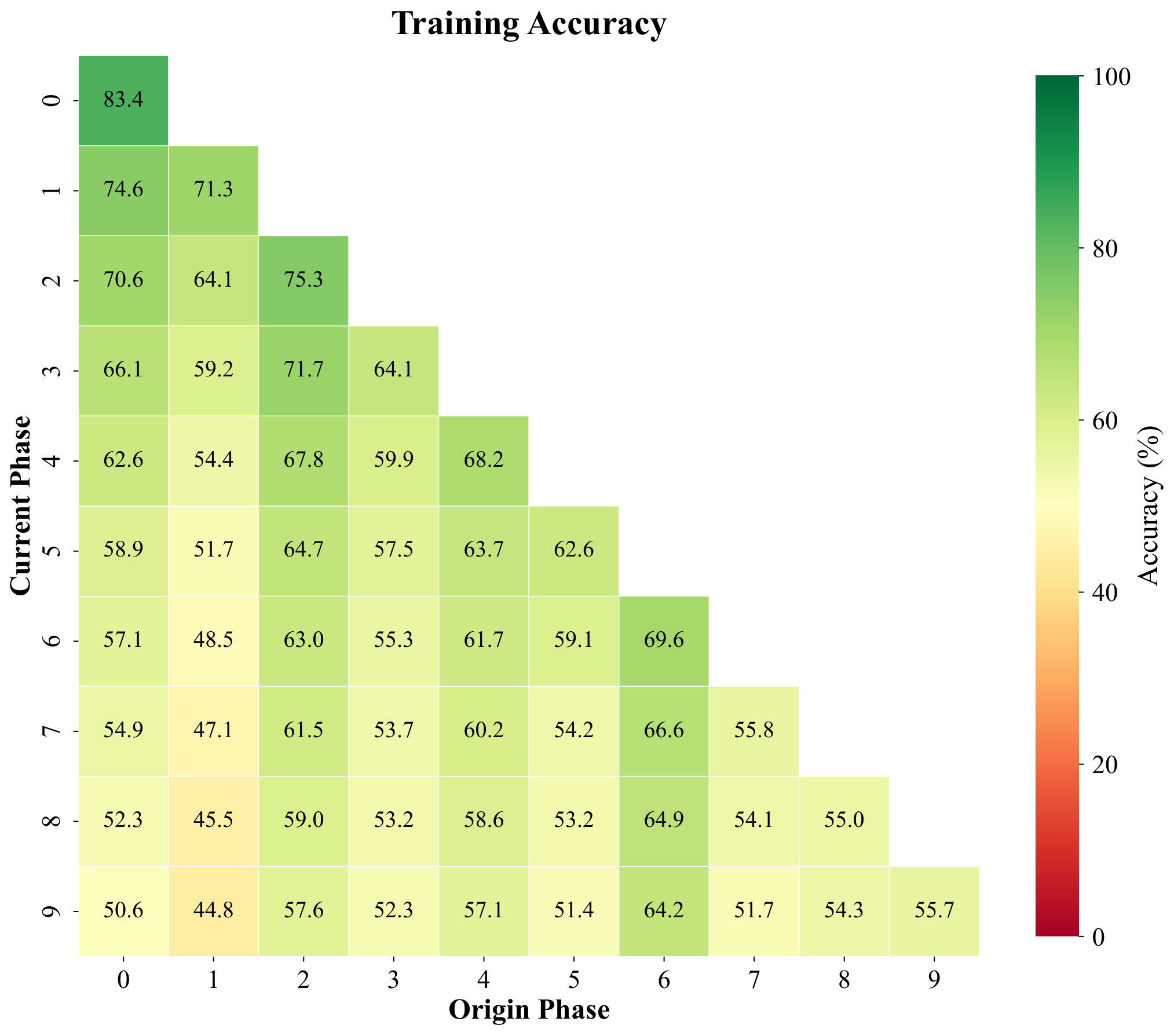
(cosine prototype)
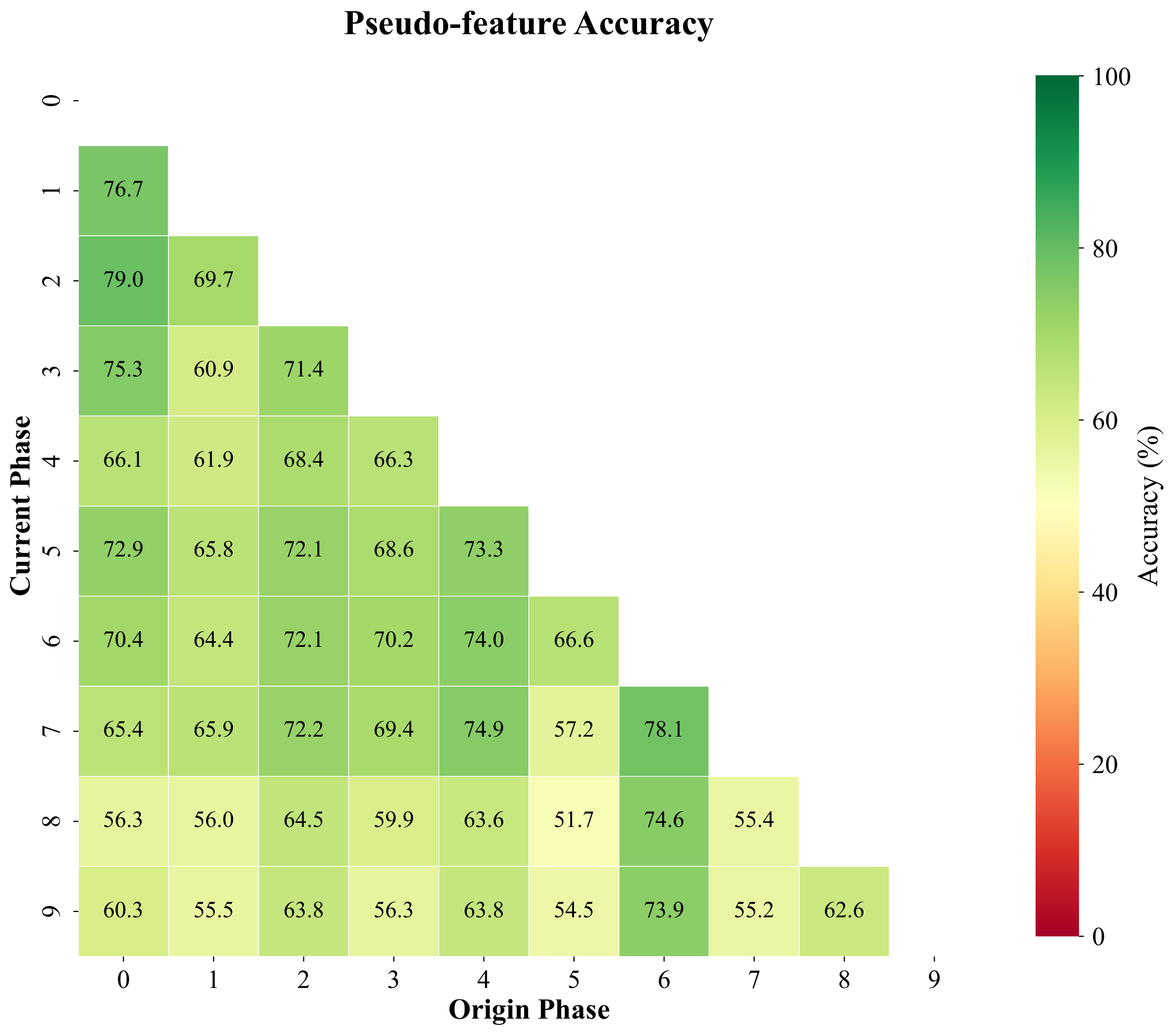
(cosine prototype)
(cosine prototype)
(test accuracy)
Row 2 — ResNet-18 trained on first-phase data only (T = 11)
(cosine prototype)
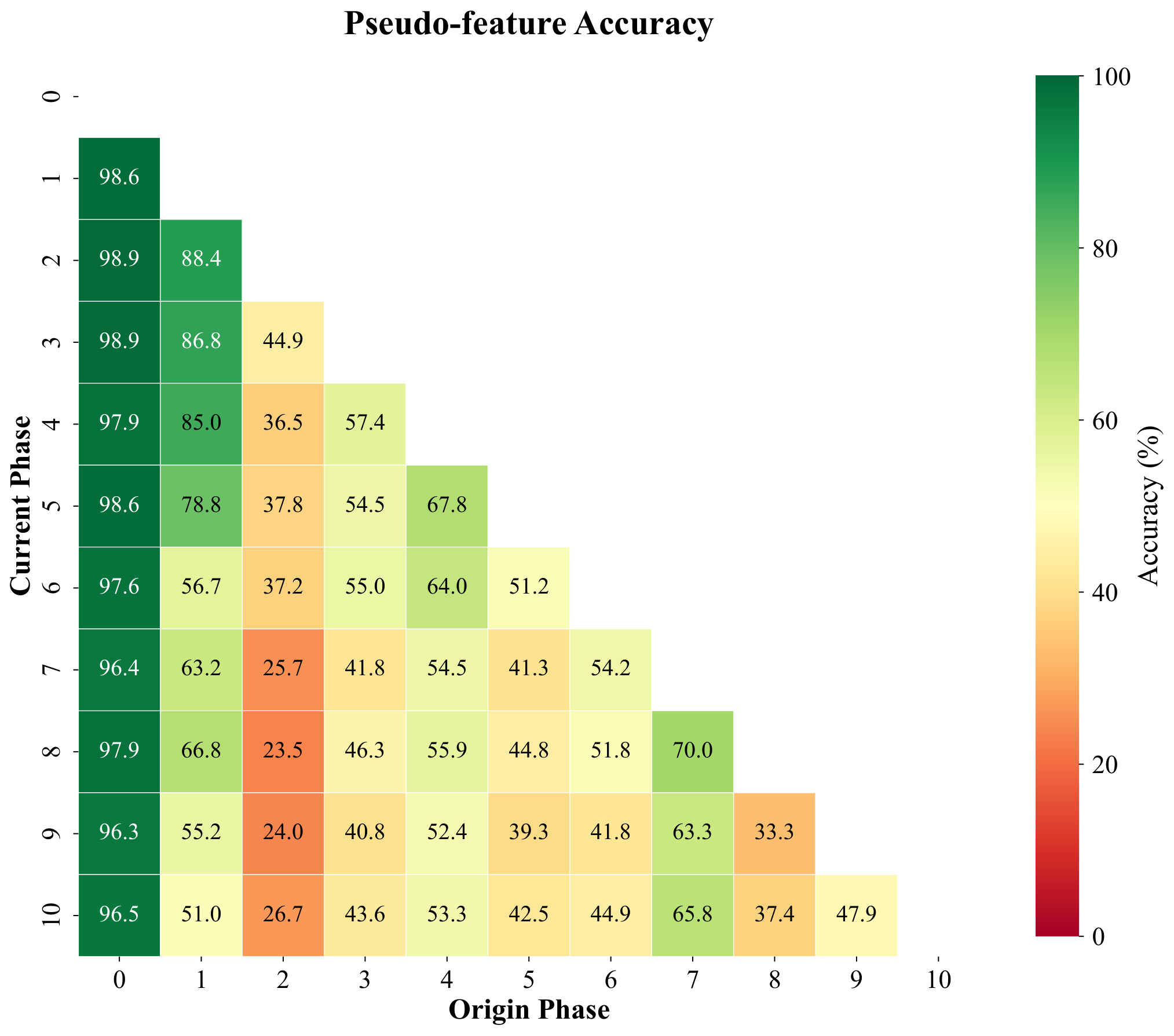
(cosine prototype)
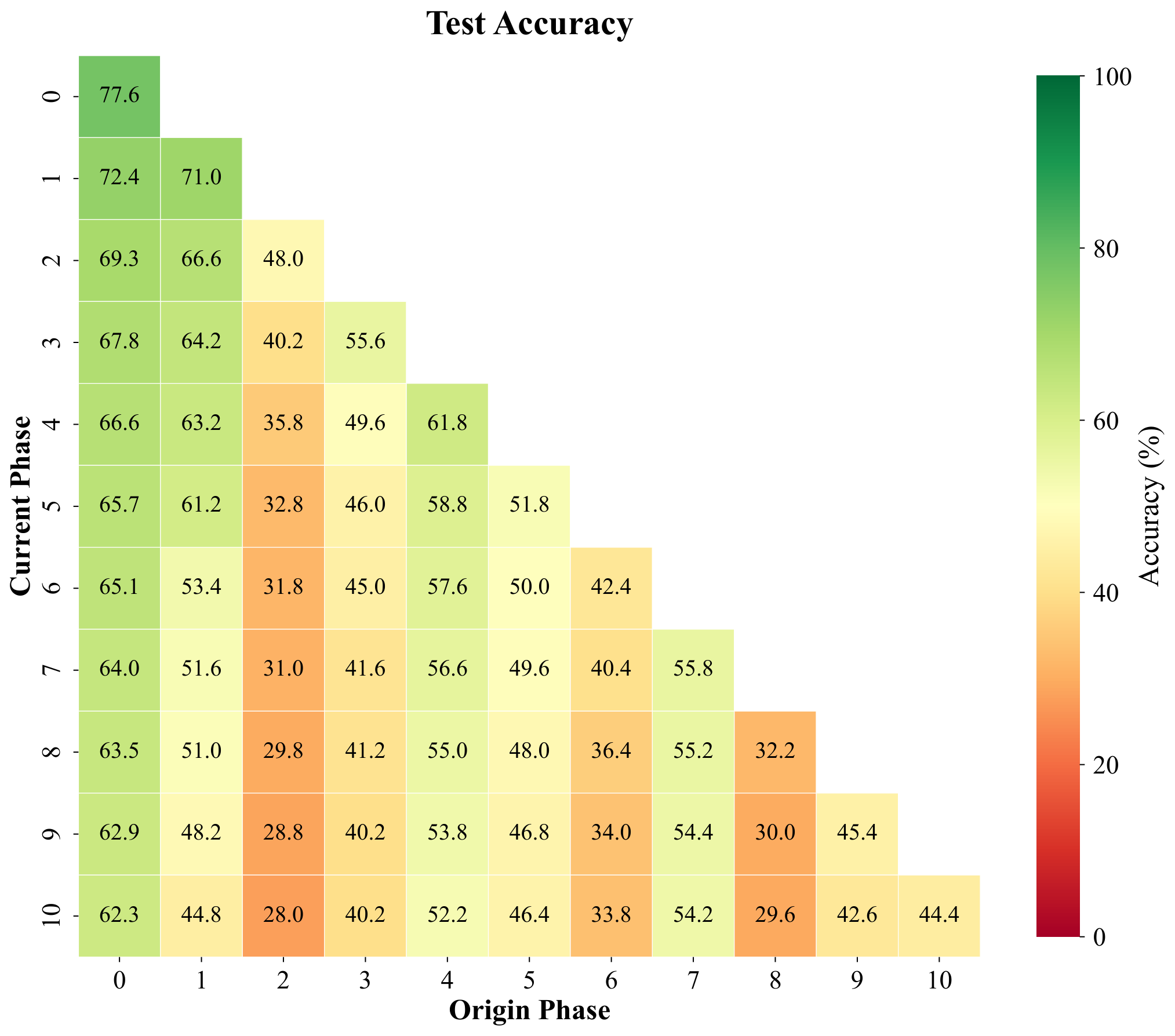
(cosine prototype)
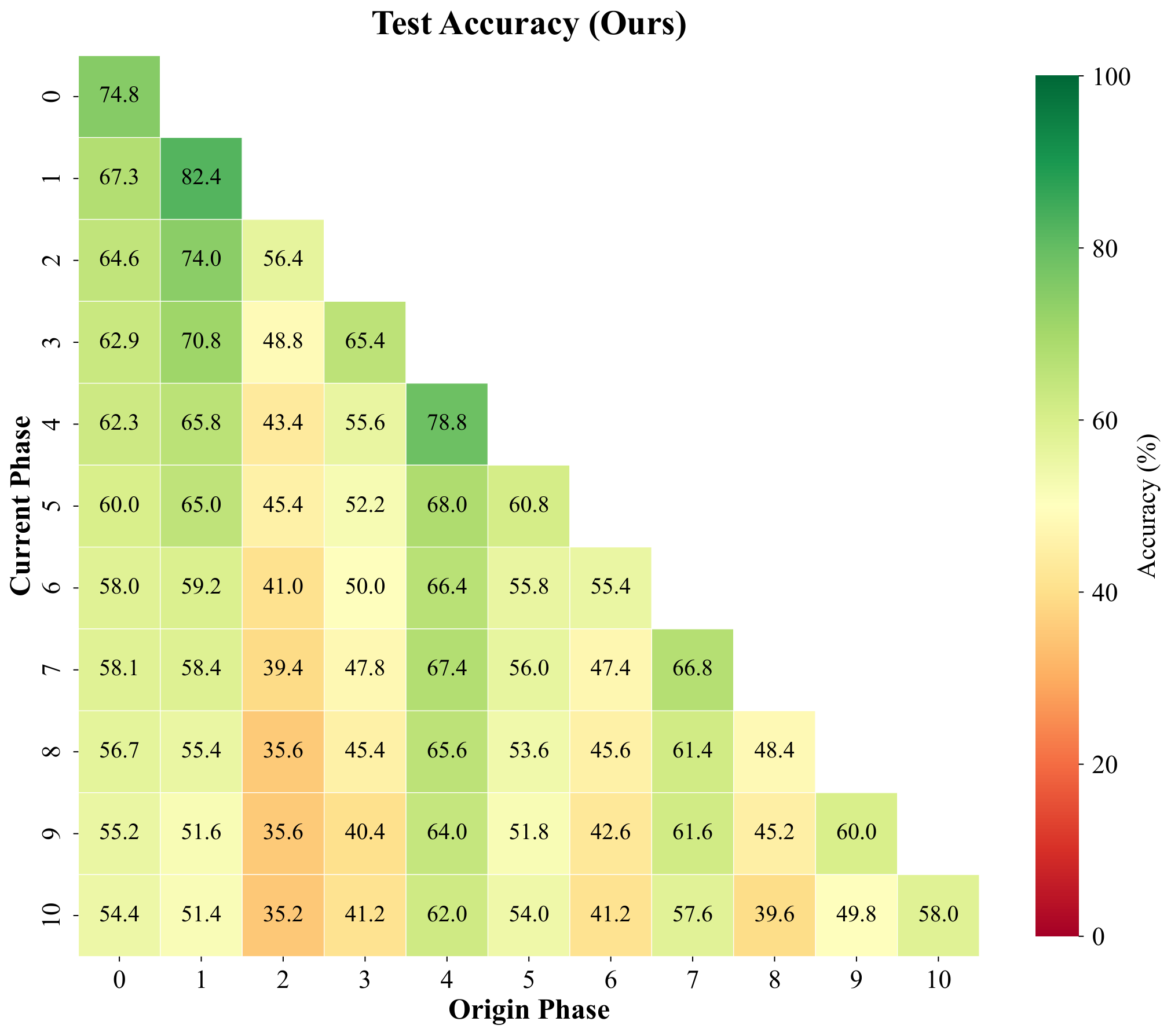
(test accuracy)
Experiment XXI. Phase-by-phase matrices under a cosine-prototype classifier on CIFAR-100: training, pseudo-feature, and validation/test alignment vs. CI-CBM test accuracy (top: ImageNet-pretrained ResNet-18, T = 10; bottom: ResNet-18 trained on first-phase data, T = 11).
Webpage template adapted from LION (NVLabs), in line with other projects in the Trustworthy ML Lab.