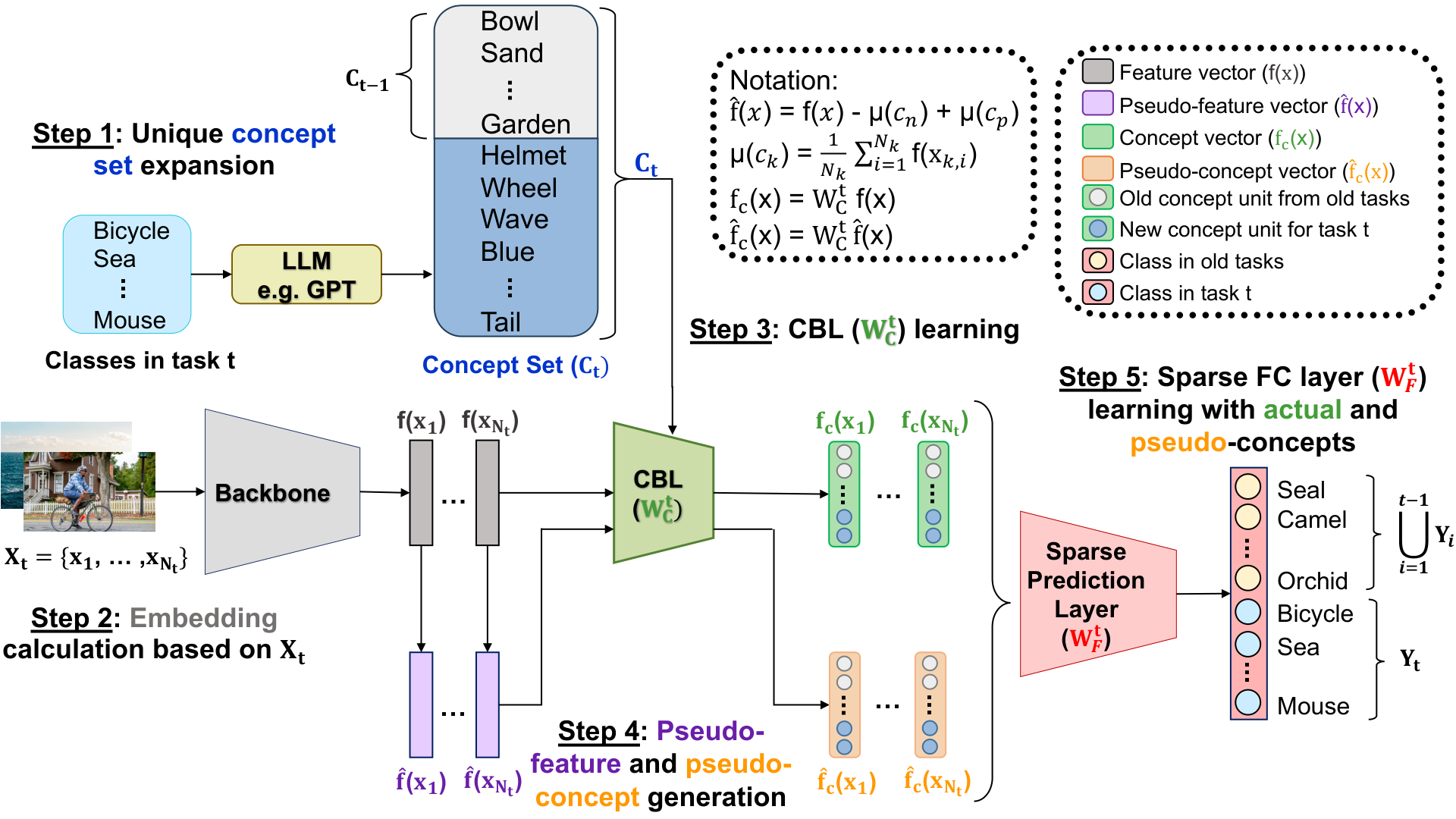
CI-CBM addresses catastrophic forgetting in class-incremental learning while keeping the model’s decisions interpretable through human-understandable concepts.
The method learns new classes without storing old training samples, using concept regularization and pseudo-concept generation to preserve previous knowledge.
Across seven datasets, CI-CBM outperforms prior interpretable continual learning methods with an average 36% accuracy gain, approaching black-box performance while remaining explainable.
Method
CI-CBM builds on label-free concept bottleneck models and adapts them to exemplar-free class-incremental learning: new classes arrive over time, old training data is not stored, and predictions stay grounded in human-readable concepts.
Step 1: Unique concept set expansion. For each new phase, CI-CBM prompts a language model for class-related concepts, removes near-duplicates and class-name-like terms with text-embedding similarity, and updates the running concept vocabulary \(C_t \leftarrow C_{t-1} \cup \{\text{filtered new concepts}\}\).
Step 2: Embedding calculation based on \(X_t\). Given the current images \(X_t\) and expanded concept set \(C_t\), CI-CBM computes the image-text alignment matrix \(P^t\), where \(P^t[i,j] = E_I(x_i)^\top E_T(c_j)\). Here, \(E_I\) is the image encoder and \(E_T\) is the text encoder.
Step 3: CBL (\(W_C^t\)) learning. The concept bottleneck layer maps frozen backbone features into concept activations, \(f_c(x)=W_C^t f(x)\), while a distillation regularizer keeps previously learned concept neurons from drifting:
Here, \(q_i^t\) is the activation of concept neuron \(i\) at phase \(t\), \(P^t_{:,i}\) is the target image-text alignment for concept \(i\), \(M_t\) is the number of concepts after expansion, \(M_{t-1}\) is the previous concept count, and \(\beta\) controls the distillation strength.
Step 4: Pseudo-feature and pseudo-concept generation. For each past class \(c_p\), CI-CBM finds the nearest new class \(c_n\), shifts features from that new-class distribution toward the stored past-class centroid, and projects the generated pseudo-features into concept space:
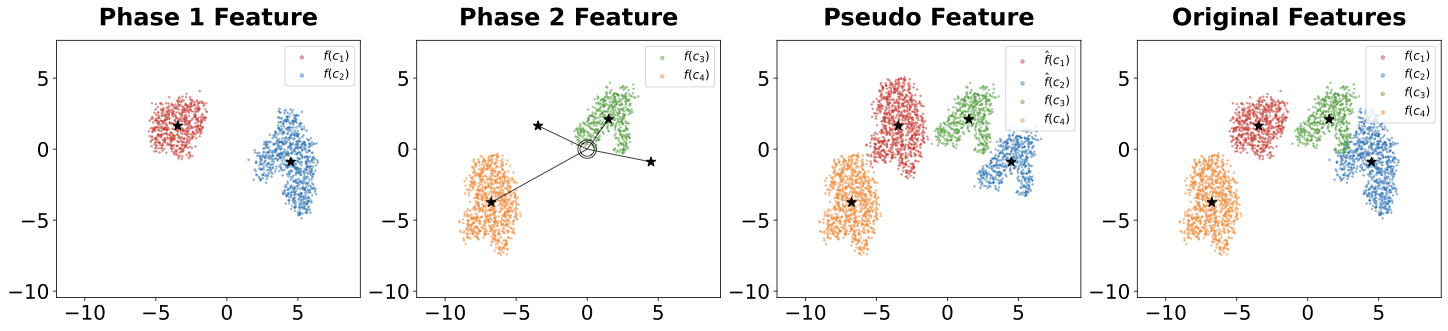
Figure 1. Pseudo-feature generation: CI-CBM shifts the nearest new-class feature distribution toward each past-class centroid to synthesize pseudo-features for old classes.
Step 5: Sparse FC layer (\(W_F^t\)) learning with actual and pseudo-concepts. The sparse final classifier is trained with actual concepts for the current phase and pseudo-concepts for previous phases:
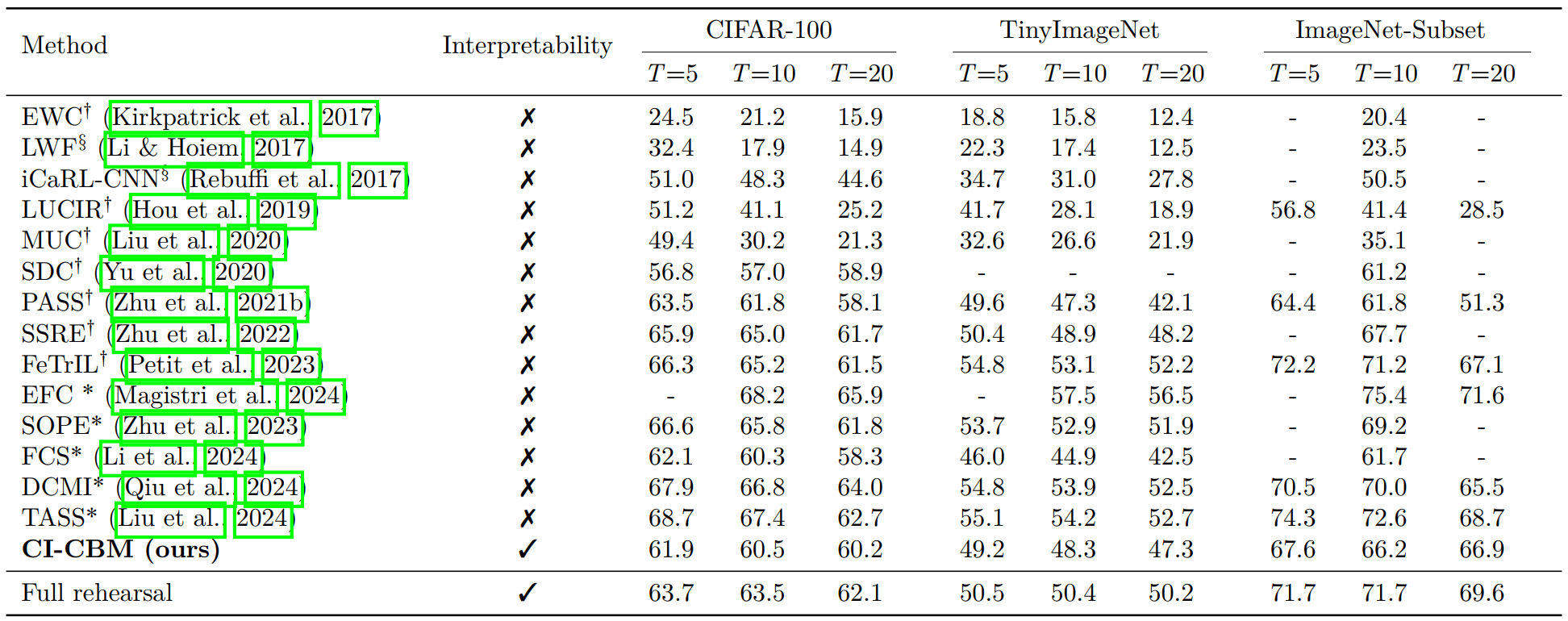
CI-CBM substantially improves average incremental accuracy over prior interpretable continual learning methods (ICICLE, IN2, CONCIL) across CIFAR-10/100, CUB, TinyImageNet, Places365, and ImageNet, while staying close to an impractical full-rehearsal upper bound that stores all past data.
Table 1. Comparison to other interpretable class-incremental methods.
2. Comparison to non-pretrained and non-interpretable methods
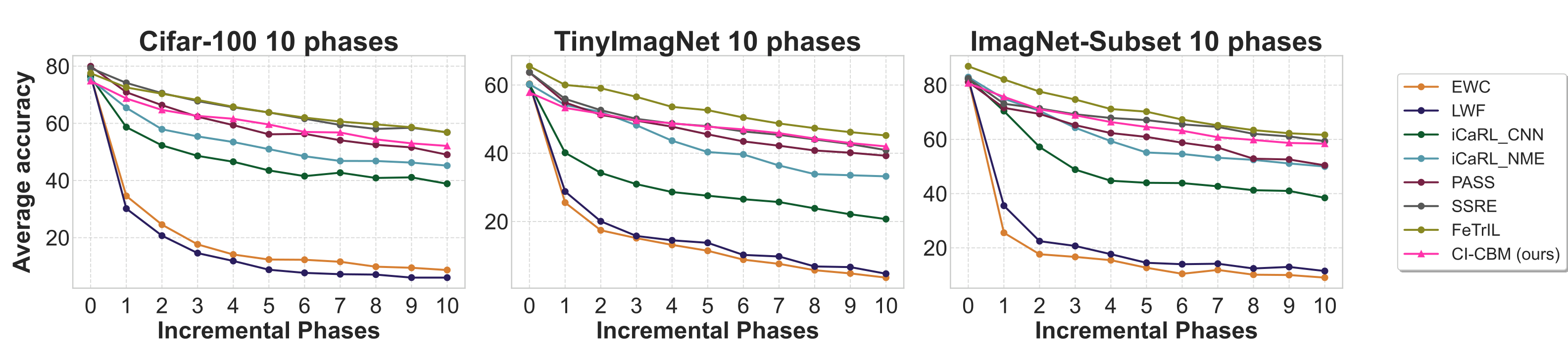
With a ResNet backbone trained from scratch in the first phase, CI-CBM remains competitive with strong unrestricted baselines; we report tabular comparisons and average-accuracy curves over incremental phases on CIFAR-100, TinyImageNet, and ImageNet-Subset.
Table 2. Comparison to exemplar-free methods without an interpretability constraint (ResNet, non-pretrained setting).
Table 3. Comparison to prompt-based EFCIL methods with a DeiT backbone trained from first-phase data (non-pretrained setting).
Figure 3. Average accuracy over incremental phases vs. unrestricted ResNet-based methods.
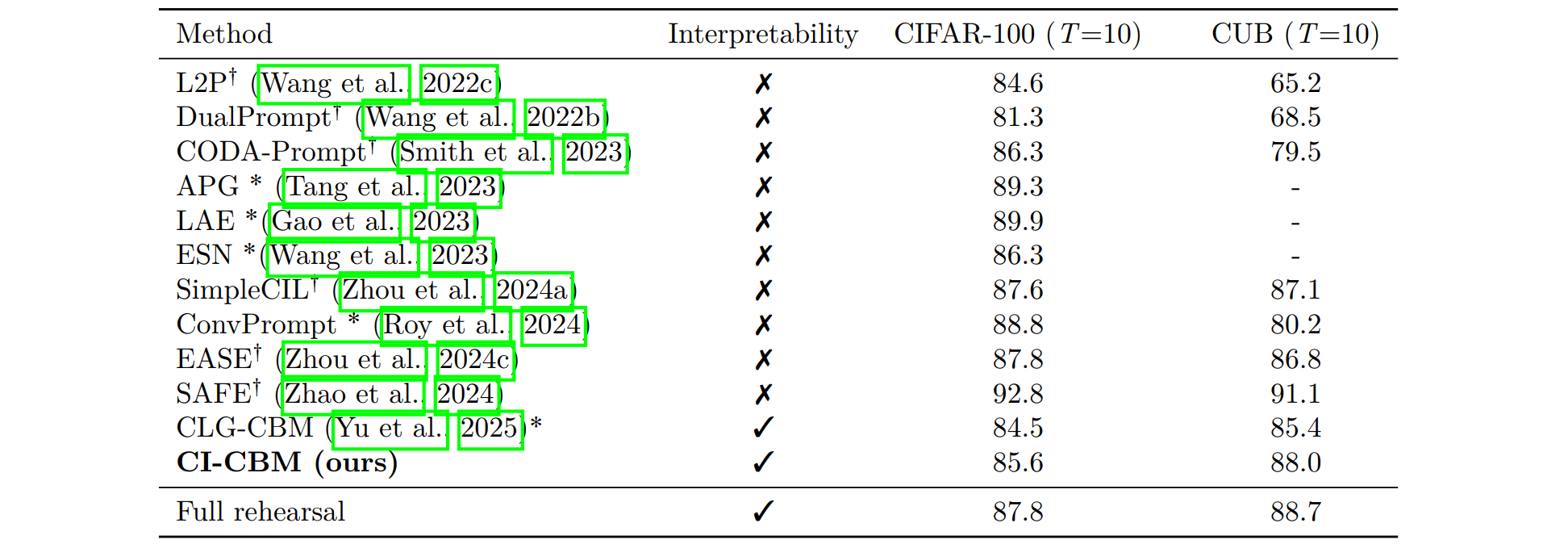
3. Comparison to pretrained ViT-based methods
Using a ViT-Base/16 backbone pretrained on ImageNet-21k, CI-CBM achieves competitive accuracy relative to state-of-the-art prompt-based continual learning methods while retaining a concept bottleneck.
4. Interpretability and insights on model reasoning
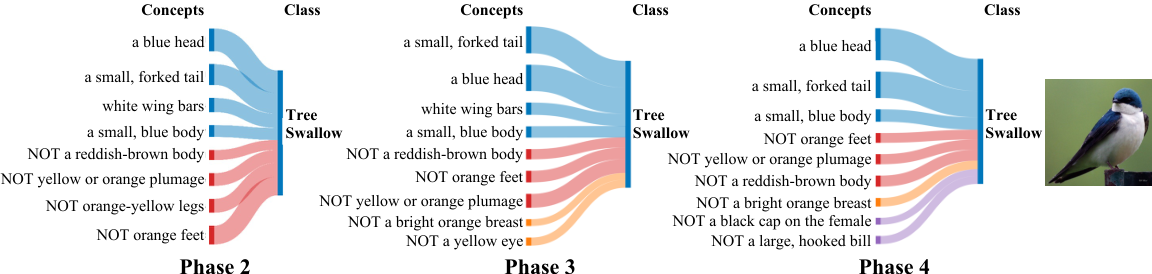
Global interpretability. CI-CBM explains each learned class through the sparse final-layer weights \(W_F^t\), which connect human-readable concept neurons to class logits. For a class \(i\), the row \(W_F^t[i,:]\) shows which concepts support the class with positive weights and which concepts oppose it with negative weights. In the visualization, line width is proportional to \(|W_F^t[i,j]|\), and negative concepts are shown as “NOT” concepts. This makes the model’s class-level decision rule inspectable across incremental phases.
Figure 4. Global view of concept-to-class weights for Tree Swallow on CUB: which interpretable concepts support or oppose the class, and how that structure appears under a multi-phase class-incremental setup.
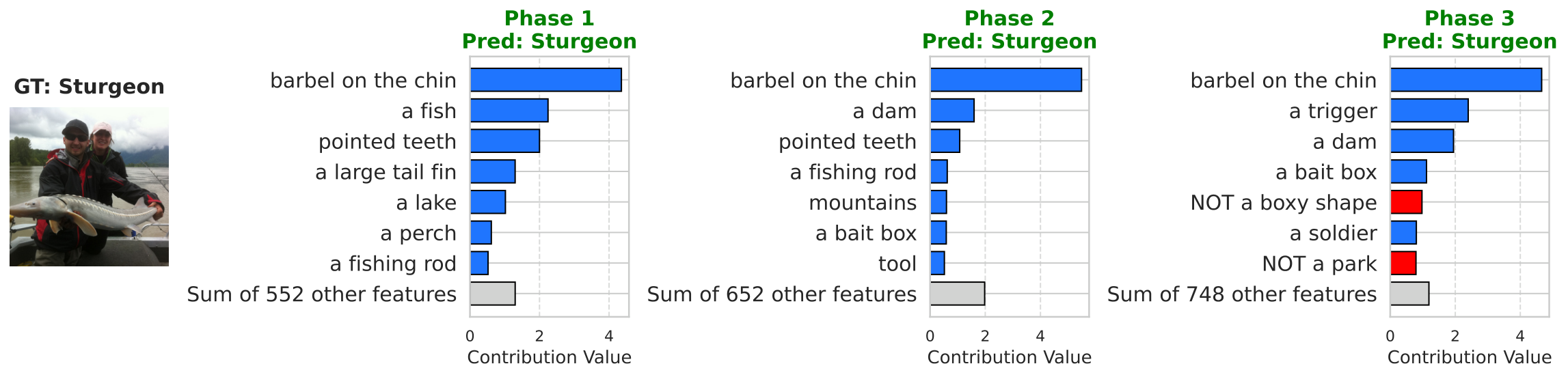
Local interpretability. CI-CBM explains an individual prediction by decomposing the class score into concept contributions. For input image \(x_k\), class \(i\), and concept \(j\), the contribution is computed as \(\text{Contrib}(x_k,i,j)=W_F^t[i,j]\times f_c^t(x_k)[j]\). Here, \(f_c^t(x_k)[j]\) is the image’s activation on concept \(j\), and \(W_F^t[i,j]\) is how strongly that concept affects class \(i\). Large positive contributions support the prediction, while negative contributions push against it. This shows why the same old-class image can remain correctly classified as new classes are introduced.
Figure 5. Local view of concept-level contributions for one image across incremental phases on ImageNet-Subset: how salient concepts for the prediction shift as more classes are learned.
Conclusion
CI-CBM shows that interpretability and strong continual learning performance can coexist, reducing the usual trade-off between accuracy and transparency.
By regularizing the concept bottleneck and generating pseudo-concepts for old classes, CI-CBM learns new classes without storing past training data.
The results demonstrate that CI-CBM is practical and flexible, working well in both pretrained and non-pretrained settings across diverse benchmarks.
@article{javadi2026ci,
title={CI-CBM: Class-Incremental Concept Bottleneck Model for Interpretable Continual Learning},
author={Javadi, Amirhosein and Oikarinen, Tuomas and Javidi, Tara and Weng, Tsui-Wei},
journal={Transactions on Machine Learning Research},
year={2026},
}