Abstract
Tool-augmented LLM agents tend to call tools indiscriminately, even when the model can answer directly. Each unnecessary call wastes API fees and latency. The goal is to reduce these unnecessary tool calls without hurting accuracy on tasks that genuinely need tools. We design a benchmark to study this problem, show that prompt engineering and reasoning both fail to selectively reduce unnecessary calls, and propose a lightweight method that exploits the model's own hidden representations to achieve this goal.
Our contributions:
- Benchmark: We design When2Tool, the first benchmark for studying tool-call decisions. It comprises 18 environments (15 single-hop, 3 multi-hop) across three categories of tool necessity with controlled difficulty levels, totaling 1,080 training and 2,700 test tasks.
- Failure Analysis: We evaluate Prompt-only and Reason-then-Act baselines, revealing that both provide limited and coarse control over tool-call decisions, with hard tasks paying a disproportionate accuracy cost for each saved call.
- Discovery & Mitigation: We probe pre-generation hidden states and find that tool necessity is linearly decodable (AUROC 0.89–0.96). We exploit this signal with Probe&Prefill, a lightweight method (<1ms overhead) that prefills the model's response based on the probe prediction. Probe&Prefill reduces tool calls by 48% with only 1.7% accuracy loss, while the best baselines either reduce only 6% at comparable accuracy (8× less efficient) or suffer 5× more accuracy loss. It also generalizes to real-world agentic search, reducing API calls by 20–56% on Search-o1.
When2Tool: A Benchmark for Tool-Call Decisions
Existing benchmarks test whether models can use tools correctly, assuming every task requires a tool. When2Tool tests whether the model knows when a tool is needed: tasks range from trivially solvable without tools to impossible without them.
18 environments across 3 categories of self-assessment:
- Category A — "Can I compute this?" (Computational scale)
- Category B — "Do I know this?" (Knowledge boundary)
- Category C — "Can I execute this reliably?" (Execution tracking)
Each with 3 difficulty levels (easy / medium / hard) creating a clear decision boundary.
The Limits of Prompting and Explicit Reasoning
We test two natural training-free approaches:
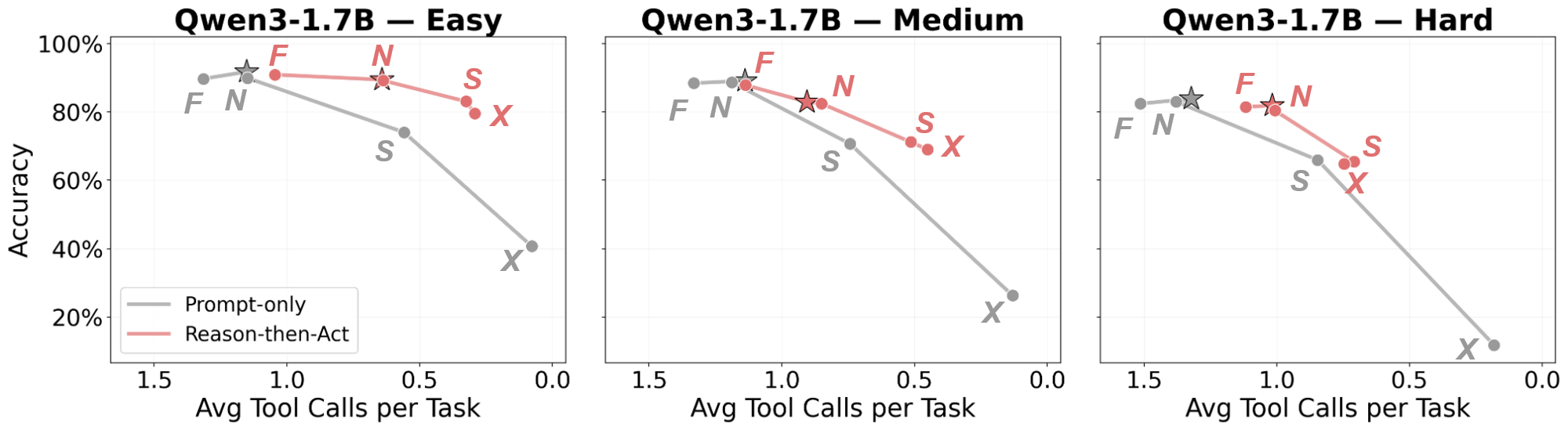
- Prompt-only — 5 modes spanning the full range of tool-use instructions: Force (F) "tool use is mandatory"; Default (★) no explicit requirements; Necessary (N) "only if necessary"; Sparse (S) "expensive, use sparingly"; No Tool (X) "do not use any tools."
- Reason-then-Act — Before making a tool-call decision, the model is instructed to first reason about whether it can solve the task directly or needs a tool, then act on its own assessment. Applied on top of each prompt mode above.
Finding: Prompt engineering reduces tool calls indiscriminately — hard tasks lose more accuracy than easy tasks. Reasoning only partially helps but completely breaks on some models (e.g., Llama).
| Qwen3-4B-Inst. | Qwen3-14B | Llama-3.3-70B | |||||||
|---|---|---|---|---|---|---|---|---|---|
| Mode / Difficulty | ΔAcc | ΔTC | ΔAcc/−ΔTC | ΔAcc | ΔTC | ΔAcc/−ΔTC | ΔAcc | ΔTC | ΔAcc/−ΔTC |
| Prompt-only Easy | −14.5 | −0.84 | −17.3 | −8.8 | −0.59 | −14.9 | +1.6 | −0.51 | +3.2 |
| Prompt-only Medium | −20.7 | −0.86 | −24.1 | −12.9 | −0.53 | −24.3 | +2.0 | −0.41 | +4.8 |
| Prompt-only Hard | −20.3 | −0.48 | −42.4 | −27.3 | −0.47 | −58.4 | −0.2 | −0.34 | −0.5 |
| Reason-then-Act Easy | −14.5 | −0.86 | −16.9 | −4.4 | −0.67 | −6.6 | −4.8 | −1.98 | −2.4 |
| Reason-then-Act Medium | −22.4 | −0.90 | −24.8 | −10.4 | −0.62 | −16.8 | −18.9 | −1.87 | −10.1 |
| Reason-then-Act Hard | −13.0 | −0.35 | −36.6 | −9.7 | −0.28 | −34.7 | −63.3 | −1.99 | −31.7 |
Probing Analysis: Decoding Implicit Tool Necessity
We probe the model's hidden state at the last input token (before any generation) with a simple linear classifier:
Finding: A linear probe achieves AUROC 0.89–0.96 across all six models — substantially exceeding the model's own verbalized reasoning. Even for Llama models where reasoning completely fails, the probe still extracts a strong signal. The model already knows, it just can't show it.
| Model | AUROC | Accuracy | AUROC by difficulty | ||
|---|---|---|---|---|---|
| Easy | Med | Hard | |||
| Qwen3-1.7B | 0.894 | 0.847 | 0.864 | 0.831 | 0.904 |
| Qwen3-4B-Inst. | 0.948 | 0.877 | 0.933 | 0.906 | 0.948 |
| Llama-3.1-8B-Inst. | 0.927 | 0.849 | 0.892 | 0.867 | 0.884 |
| Qwen3-14B | 0.957 | 0.892 | 0.955 | 0.907 | 0.941 |
| Qwen3-32B | 0.952 | 0.885 | 0.951 | 0.903 | 0.939 |
| Llama-3.3-70B-Inst. | 0.936 | 0.872 | 0.906 | 0.849 | 0.956 |
Probe&Prefill: Turning Hidden Knowledge into Better Decisions
A lightweight inference-time method that translates the probe signal into better tool-call decisions, requiring no fine-tuning and no reasoning overhead:
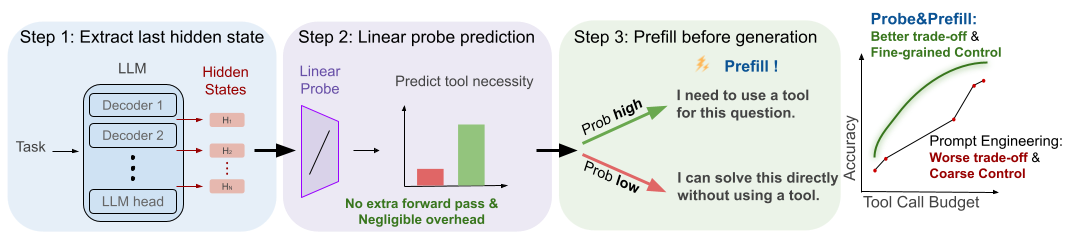
Step 1: Extract last hidden states
Run a single forward pass over the input tokens and extract hidden states at the last token position. This is the standard prompt-encoding step for KV cache, so extraction adds no additional forward passes.
Step 2: Linear probe prediction
Apply the trained linear probe to all-layer hidden states, producing probability \(p\). Threshold \(\tau\) converts this to a binary decision: if \(p < \tau\), the task is solvable without tools; otherwise a tool call is necessary. Sweeping \(\tau\) provides smooth control over the accuracy–efficiency tradeoff.
Step 3: Prefill before generation
Prepend a steering sentence to the model's response based on the probe decision:
- If \(p < \tau\) (tool unnecessary):
"I can solve this directly without using a tool." - If \(p \geq \tau\) (tool necessary):
"I need to use a tool for this question."
The model continues generating from this prefill.
Finding: Probe&Prefill achieves a strictly better accuracy–tool-call tradeoff than all baselines. By sweeping \(\tau\), it traces a smooth Pareto curve—unlike prompt engineering which offers only a few discrete operating points. At \(\tau\)=0.5, it reduces tool calls by 48% with only 1.7% accuracy loss. The probe selectively skips easy calls while preserving hard ones, yielding 8× better efficiency than the best baseline.
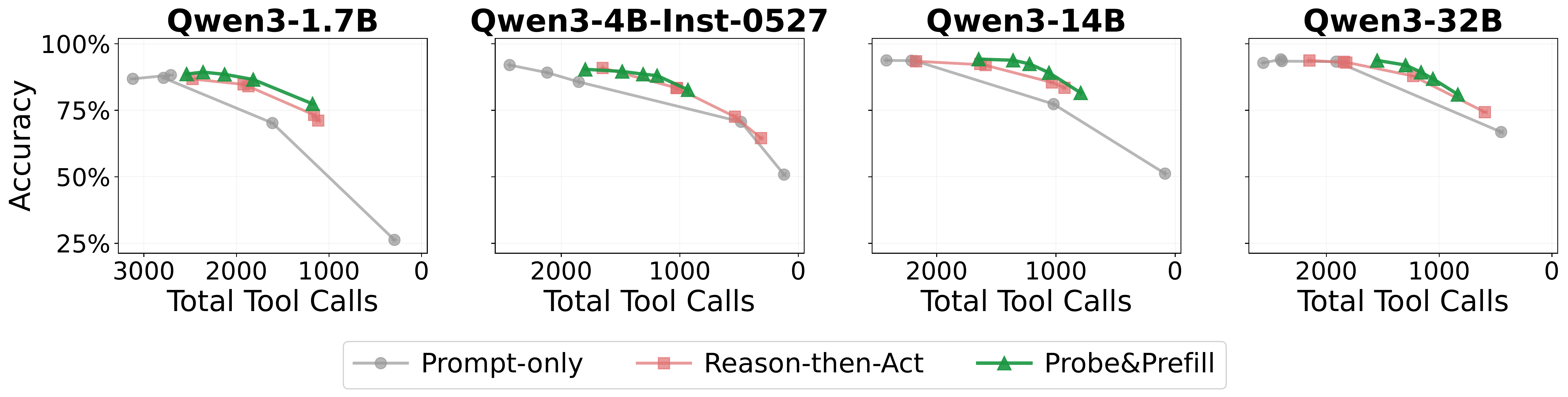
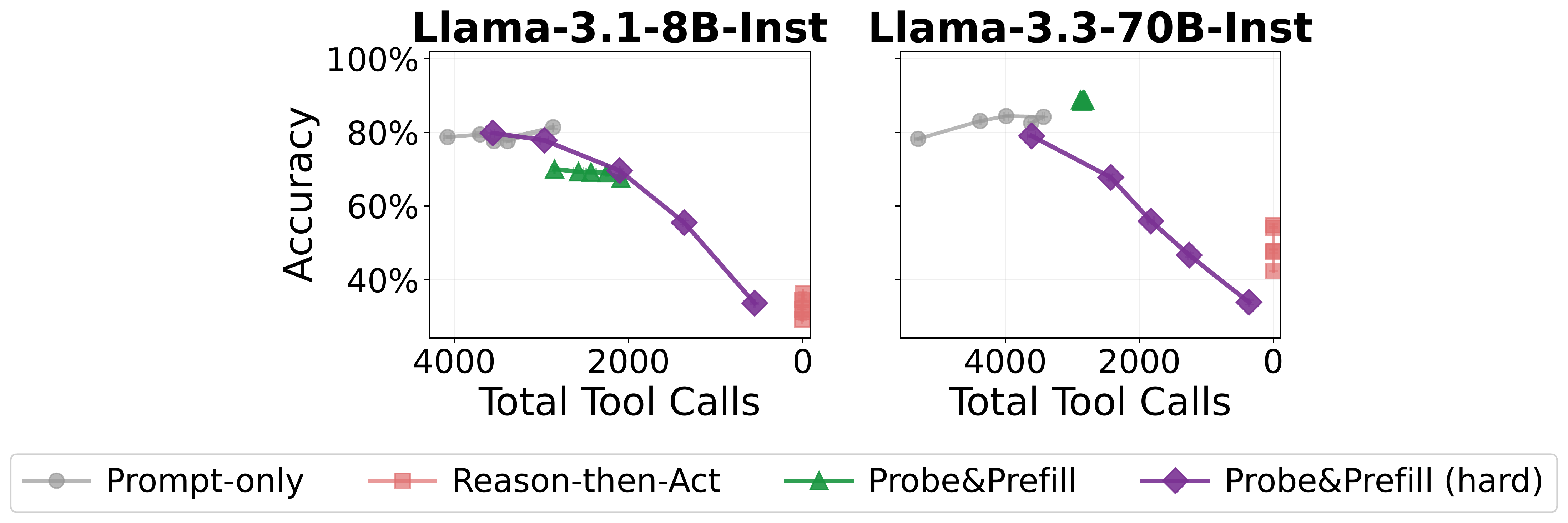
| Easy | Medium | Hard | Overall | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Method | ΔAcc | ΔTC | ΔAcc/−ΔTC | ΔAcc | ΔTC | ΔAcc/−ΔTC | ΔAcc | ΔTC | ΔAcc/−ΔTC | ΔAcc | ΔTC | ΔAcc/−ΔTC |
| Necessary (N) | −0.3 | −0.09 | −3.5 | −0.7 | −0.04 | −17.9 | −1.9 | −0.04 | −44.4 | −1.0 | −0.06 | −16.8 |
| Necessary + Reason-then-Act | −8.1 | −0.95 | −8.5 | −16.3 | −0.82 | −19.7 | −23.2 | −0.70 | −32.9 | −15.8 | −0.82 | −19.2 |
| Sparse (S) | −6.3 | −0.55 | −11.3 | −7.9 | −0.47 | −16.9 | −11.1 | −0.35 | −31.5 | −8.4 | −0.46 | −18.4 |
| Sparse + Reason-then-Act | −9.9 | −1.13 | −8.8 | −19.9 | −1.04 | −19.1 | −29.3 | −0.84 | −34.7 | −19.7 | −1.00 | −19.6 |
| No Tool (X) | −18.1 | −0.72 | −25.2 | −26.7 | −0.72 | −36.9 | −41.4 | −0.69 | −60.4 | −28.7 | −0.71 | −40.5 |
| No Tool + Reason-then-Act | −12.4 | −1.18 | −10.5 | −23.5 | −1.12 | −20.9 | −36.6 | −0.94 | −39.1 | −24.2 | −1.08 | −22.4 |
| Probe&Prefill (Ours) | −1.1 | −0.66 | −1.6 | −3.4 | −0.54 | −6.2 | −0.8 | −0.24 | −3.4 | −1.7 | −0.48 | −3.6 |
BibTeX
@article{sun2026when2tool,
title={LLM Agents Already Know When to Call Tools -- Even Without Reasoning},
author={Sun, Chung-En and Liu, Linbo and Yan, Ge and Wang, Zimo and Weng, Tsui-Wei},
journal={arXiv preprint arXiv:2605.09252},
year={2026},
url={https://arxiv.org/abs/2605.09252}
}