The Importance of Prompt Tuning for Automated Neuron Explanations
Abstract
Recent advances have greatly increased the capabilities of large language models (LLMs), but our understanding of the models and their safety has not progressed as fast.
In this paper we aim to understand LLMs deeper by studying their individual neurons. We build upon a recent work [1] from Open AI showing large language models such as GPT-4 can be useful in explaining what each neuron in a language model does. Specifically, we analyze the effect of the prompt used to generate explanations and show that reformatting the explanation prompt in a more natural way can significantly improve neuron explanation quality and greatly reduce computational cost. We demonstrate the effects of our new prompts in three different ways, incorporating both automated and human evaluations.
Method
Overview of the neuron explanation pipeline and our proposed prompts (in green) to highly improve the explanation quality and efficiency.

Proposed prompting methods:
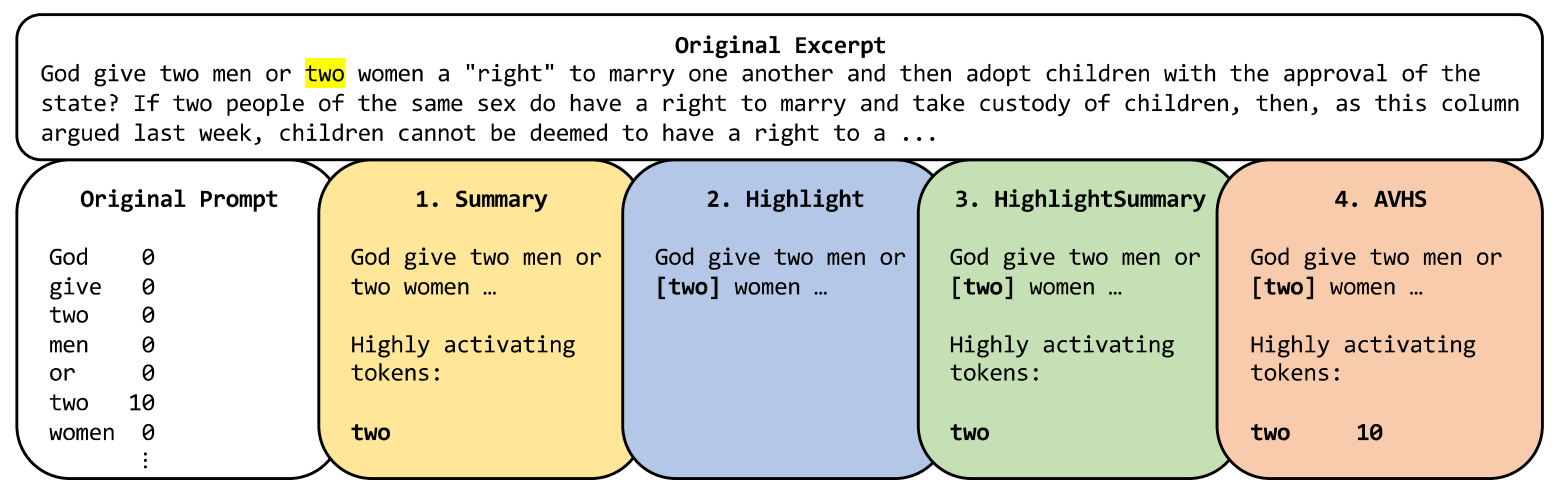
Below illustrates how an example text excerpt is converted to a prompt. This prompt is what the explainer model receives and uses to generate an appropriate explanation.
The first prompt (in white) is the Original prompt used in the OpenAI blog [1], and the next 4 (colored) are our proposed prompts. Note the differences in how the highly activating tokens are expressed in each prompt.
Experiment Results
1. Token Usage Differences:
Before the API processes the prompts, the input is broken down into tokens, or parts of words. Our proposed prompting methods show significant improvement in token usage over the Original prompt, decreasing API costs and computation time.

2. Simulate and Score:
In order to test accuracy of generated explanations, explanations are simulated then scored against the true activations for each excerpt.
A simulator model is given the generated explanation along with the text excerpt and asked to predict the activating tokens.
The predicted activations are compared to the true activations to calculate accuracy.
We evaluate at two sets of neurons in below table, and bolded number is the highest score for each column:
* Random - tested neurons are randomly chosen without a score threshold.
* Random Interpetable - tested neurons are randomly chosen from the pool of neurons with a score higher than 0.35, which is considered reasonably "interpretable".
It can be seen that with GPT-3.5 as the explainer model, our Summary prompting method consistently scored highest. With GPT-4 as the explainer model, both the Highlight and Original prompting methods scored high.

3. Ada + Cosine Similarity:
Another method of testing accuracy of generated explanations is AdaCS. Both the generated explanation and a predetermined "ground truth" explanation for the neuron are converted into text embeddings or word vectors by OpenAI's Ada model. The word vectors are then compared through cosine similarity to determine accuracy.
In addition to the Random neurons and Random Interpretable neurons defined above, we also evaluate on another two sets of neurons in the below table, where bolded is the highest score for each column:
* Top 20 per layer - top 20 highest scoring neurons from each layer
* Top 1k - top 1000 highest scoring neurons from the entire neural network
It can be seen that on average, the HighlightSummary (HS) prompting method scored highest.

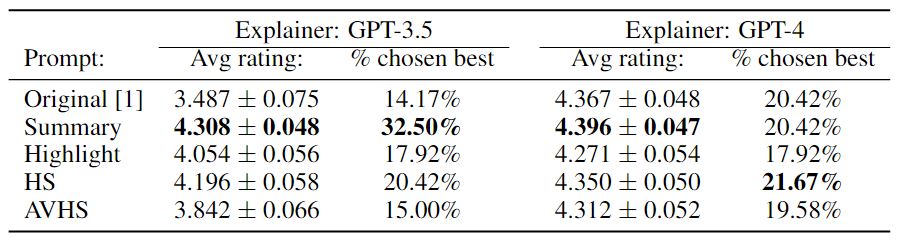
4. Human Evaluation:
Subjects were given a text excerpt and its highly activating tokens along with 5 generated explanations, one for each prompting method. They were asked to rank each explanation from 1-5 (5 being best) and choose one explanation that they felt best described the text excerpt and its activations.
We bolded the numbers that is the highest score for each column. It can be seen in the below table that on average, our proposed Summary prompting method scored highest, while HighlightSummary (HS) prompt's explanation had the highest percentage chosen as best.