Beyond Top Activations:
Efficient and Reliable Crowdsourced Evaluation
of Automated Interpretability
Abstract
- Interpreting individual neurons or directions in activation space is an important topic in mechanistic interpretability.
Numerous automated interpretability methods generate text explanations of neurons, but it remains unclear how reliable
these explanations are, and which methods produce the most accurate descriptions.
- While crowd-sourced evaluations are commonly used, existing pipelines are noisy, costly, and typically assess only the
highest-activating inputs, leading to unreliable results.
- We introduce two techniques to enable cost-effective and accurate crowdsourced evaluation beyond top activating inputs.
First, Model-Guided Importance Sampling (MG-IS) selects the most informative inputs to show raters,
reducing the number of inputs needed by ~13×. Second, Bayesian Rating Aggregation (BRAgg)
addresses label noise, reducing the number of ratings per input required to overcome noise by ~3×.
- Together, these techniques reduce evaluation cost by ~40×, making large-scale evaluation feasible. We use
our methods to conduct a large scale crowd-sourced study and systematically compare recent automated interpretability methods for
deep vision networks.
Overview
To assess the quality of neuron explanations, researchers often rely on crowd-sourced human studies (e.g. via Amazon Mechanical Turk).
We aim to evaluate explanations using a principled metric — the correlation coefficient between neuron activations
\(a_k\) and concept (explanation) presence labels \(c_t\) — rather than only checking whether an explanation matches a neuron's
top activating inputs. However, computing this full-distribution metric reliably introduces two challenges that drive up cost:
- Challenge 1 — High Labeling Cost. Computing correlation requires concept
presence labels across the entire probing dataset. Labeling a 50,000-image dataset for a single (neuron, explanation) pair
costs ~$600, and evaluating a few thousand neurons can reach ~$1M.
- Challenge 2 — Rater Noise. Human concept judgments are noisy, and even
small error rates can significantly affect correlation scores, particularly for rare concepts.
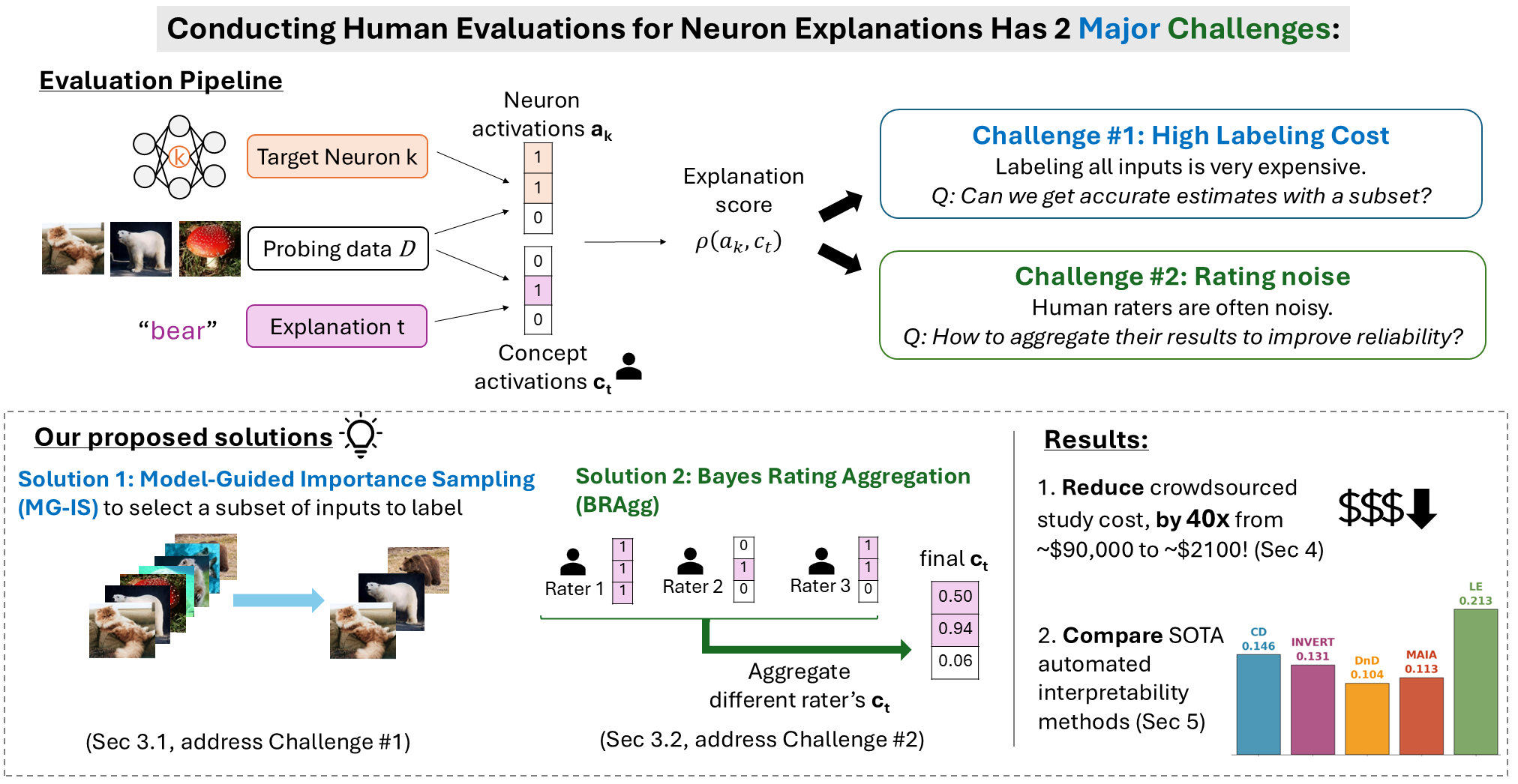
Fig 1: Overview of the explanation evaluation pipeline. We focus on two main challenges:
1: How to reduce high labeling cost? and 2: How to effectively handle noisy ratings?
Our proposed solutions are MG-IS and BRAgg.
Methods
(I) Model-Guided Importance Sampling (MG-IS)
Concepts of interest are often
rare in the probing dataset, so a uniform (Monte Carlo) sample is unlikely to contain
enough positive examples to estimate correlation accurately. Instead, we use
importance sampling, drawing inputs
from a proposal distribution \(\mathcal{Q}\) that places higher probability on informative inputs. The variance-minimizing optimal
proposal samples each input proportionally to its contribution to the correlation:
\[ q^{*}(x_i) \propto |\bar{a}_{ki} \cdot \bar{c}_{ti}| \]
Since the true concept labels \(c_t\) are unknown before the study, we approximate them with a cheap model
(
SigLIP) to guide sampling, mixing with the uniform distribution to keep the estimator unbiased:
\[ q^{\text{MG-IS}}(x) = (1-\gamma)\, q^{\text{siglip}}(x) + \gamma\, p(x), \qquad \gamma = 0.2 \]
We then apply the importance-sampling correction \(\frac{p(x)}{q(x)}\) to obtain an unbiased estimate of the correlation.
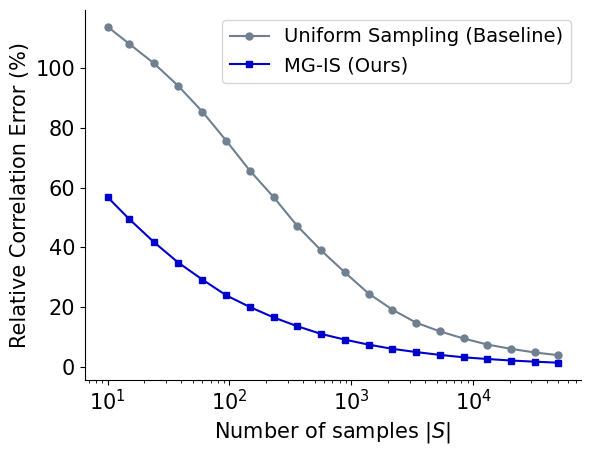
Fig 2: Comparing sampling strategies for estimating the correlation. Our
MG-IS using SigLIP estimates significantly outperforms the baseline regardless of subset size,
matching uniform-sampling accuracy with ~15× fewer samples.
(II) Bayes Rating Aggregation (BRAgg)
Crowd-sourced concept labels are noisy due to variability in rater attention, interpretation, and experience. To handle this, we collect
\(m\) independent binary ratings per input and aggregate them. Rather than simple Averaging or Majority Vote, BRAgg
estimates \([c_t]_i\) as the posterior probability that the concept is truly present given the ratings \(R_{ti}\):
\[ [c_t]_i = \mathbb{P}([c_t^{*}]_i = 1 \mid R_{ti}) =
\frac{\mathbb{P}(R_{ti} \mid C_{ti})\,\mathbb{P}(C_{ti})}{\mathbb{P}(R_{ti}\mid C_{ti})\,\mathbb{P}(C_{ti}) + \mathbb{P}(R_{ti}\mid \lnot C_{ti})\,\mathbb{P}(\lnot C_{ti})} \]
The likelihood assumes each rater errs at rate \(\eta\) (estimated as ~23% on MTurk), and the prior
\(\mathbb{P}(C_{ti})\) can be uniform (\(\beta=0.05\)) or initialized from a cheap SigLIP evaluator — yielding a hybrid that combines
human ratings with model knowledge.
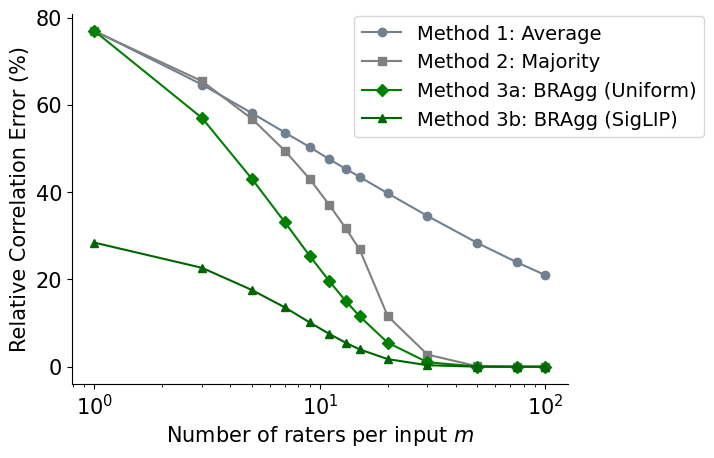
Fig 3: Comparison of rating aggregation strategies (simulated study, error rate \(\eta=23\%\)).
BRAgg (SigLIP) achieves the lowest error and can reach a target accuracy with
2–10× fewer raters than the best baseline.
Validation: Combining MG-IS and BRAgg
We validate our techniques in two realistic settings with both label noise and limited samples:
a simulation with 23% label noise, and a real crowd-sourced study on Amazon Mechanical Turk (10 ResNet-50 neurons,
600 inputs each, 9 raters per input, with ground-truth ImageNet labels for comparison).
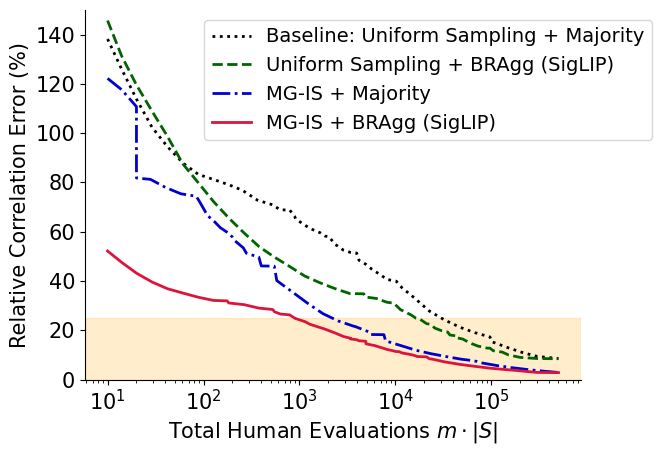
(a) Simulation with 23% label noise.
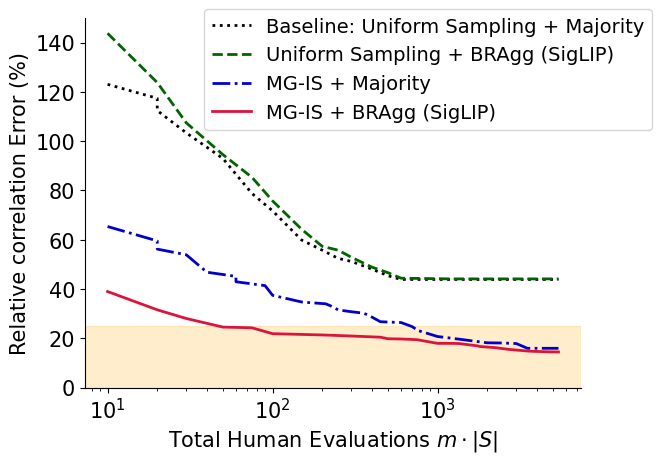
(b) Mechanical Turk validation study.
Fig 4: Effect of MG-IS and BRAgg, individually and together. The best results come from using
MG-IS + BRAgg together.
- Using MG-IS + BRAgg together by far outperforms either technique alone. In the simulation, reaching the
same error requires 3× more evaluations with MG-IS only, 25× with BRAgg only, and 40× with the
uniform-sampling + majority-vote baseline.
- This ~40× cost reduction brings the cost of a systematic study down from ~$90,000 to $2,160
(just $2.16 per neuron-explanation pair).
- SigLIP-only automated evaluation is a reliable cheap alternative (only ~15% higher error than our human study), but human
evaluation remains the gold standard.
Large-Scale Crowdsourced Study
Using our methods, we conducted a large-scale study on neurons in ResNet-50 (Layer4) and ViT-B-16 (Layer11 MLP),
both trained on ImageNet. We first used SigLIP-based automated evaluation to select the 5 best-performing methods, then ran a
crowd-sourced study over 100 neurons per model, 180 inputs per neuron, 3 raters each — 1000 (neuron, explanation) pairs
for a total cost of $2,160.
Automated Evaluation (SigLIP simulation, single-concept explanations)
| Model |
ND | MILAN | CD | INVERT | DnD | MAIA | LE (label) | LE (SigLIP) |
| RN-50 (Layer4) |
0.124 | 0.092 | 0.190 | 0.187 | 0.153 | 0.140 | 0.179 |
0.241 |
| ViT-B-16 (Layer11 MLP) |
0.034 | 0.019 | 0.185 | 0.134 | 0.105 | 0.150 | 0.270 |
0.297 |
Table 1: SigLIP-based simulation with correlation scoring (\(l=1\)).
Best in bold, second best underlined.
Linear Explanations (LE) performs best even when restricted to single-concept explanations.
Crowdsourced Results
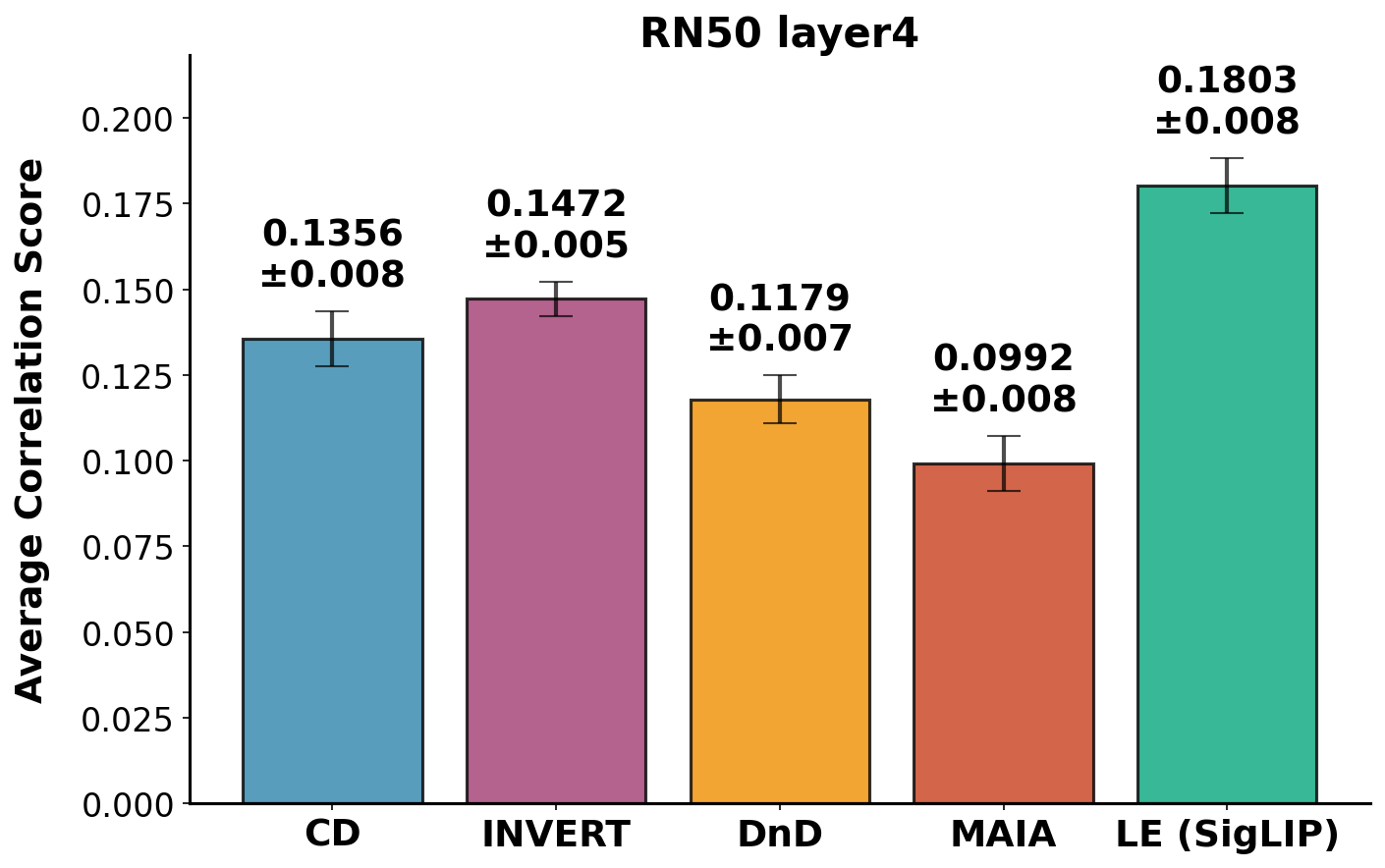
(a) ResNet-50 (Layer4).
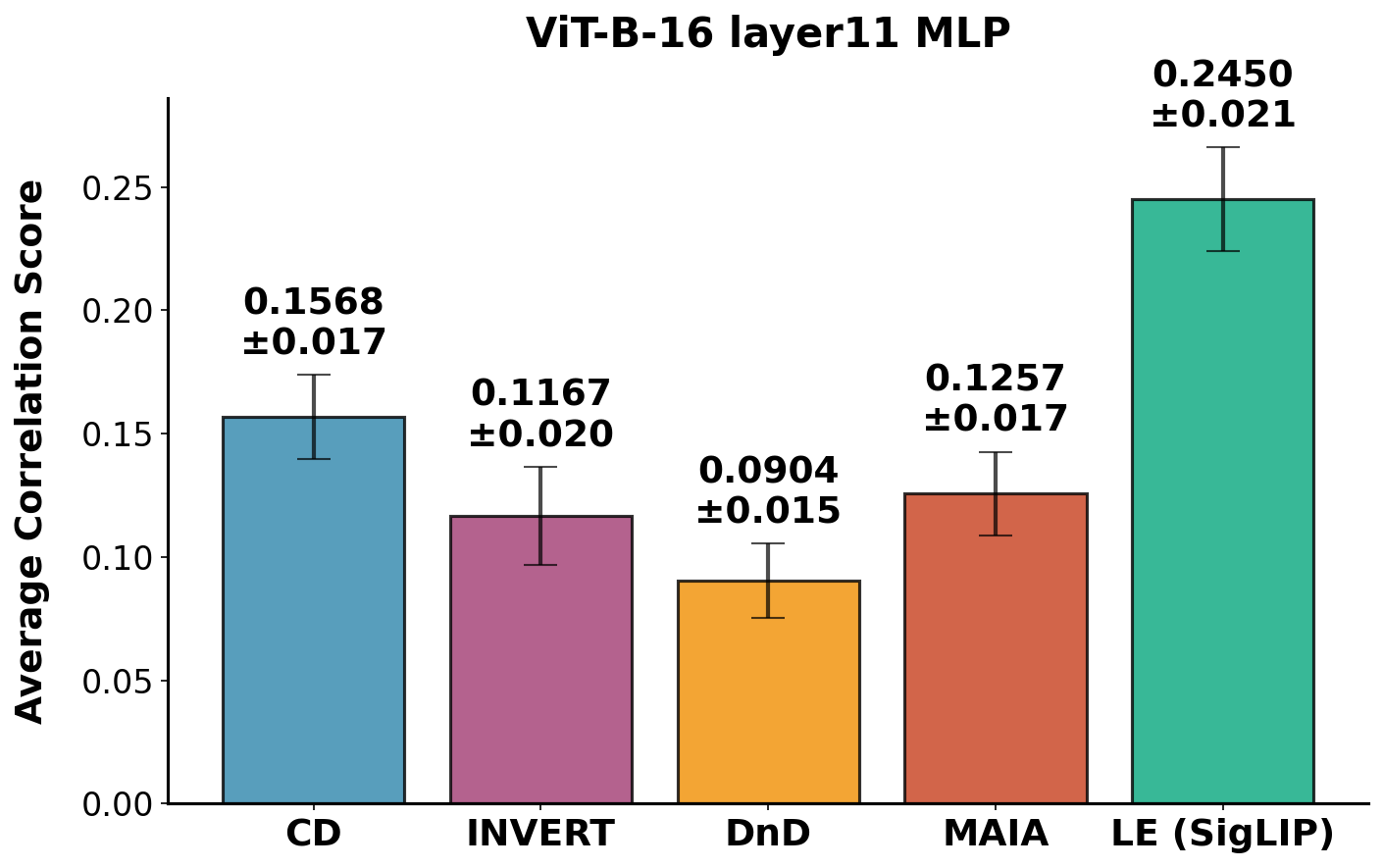
(b) ViT-B-16 (Layer11 MLP).
Fig 5: Results of our MTurk study using BRAgg (SigLIP) for rating aggregation.
Overall, Linear Explanations (LE) achieve the highest correlation coefficient.
- Linear Explanations perform best overall, likely because it is the only tested method optimized to explain the
entire range of activations rather than only the highest activations.
- Recent LLM-based methods (MAIA, DnD) did not outperform simpler baselines, due to their focus on highly-activating
inputs (overly specific explanations) and higher variance in description quality.
- Overall correlation scores were quite low (~0.2 at best), highlighting the need for further improvement in explanation methods
and/or more interpretable models.
Study Interface
In each task, raters are shown an explanation \(t\) and 15 inputs, and asked to select the inputs where the concept is present.
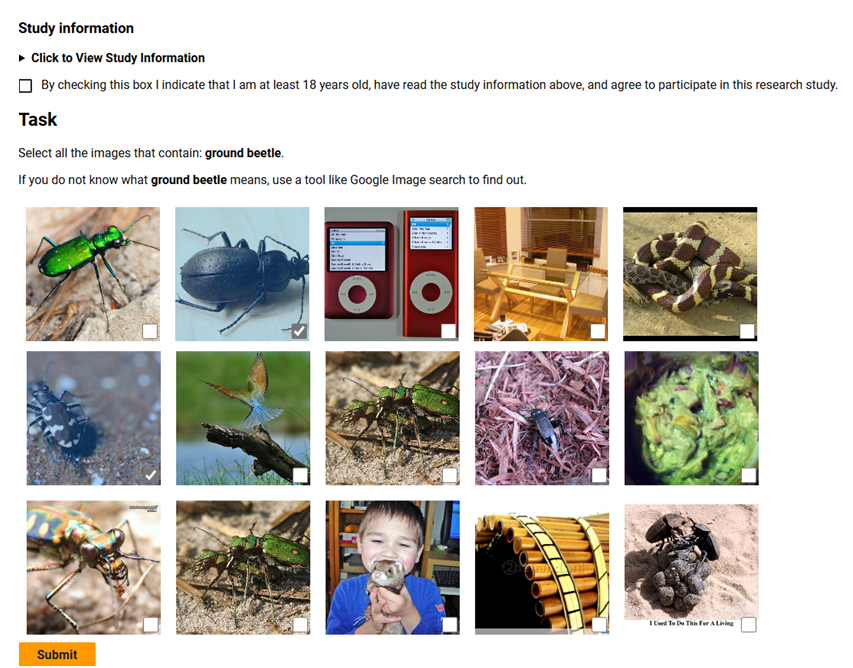
Fig 6: The crowd-sourced study interface used on Amazon Mechanical Turk.
Cite this work
T. Oikarinen, G. Yan, A. Kulkarni and T.-W. Weng, Beyond Top Activations: Efficient and Reliable Crowdsourced Evaluation of Automated Interpretability, CVPR 2026.
@inproceedings{oikarinen2026beyond,
title={Beyond Top Activations: Efficient and Reliable Crowdsourced
Evaluation of Automated Interpretability},
author={Oikarinen, Tuomas and Yan, Ge and Kulkarni, Akshay and Weng, Tsui-Wei},
booktitle={Proceedings of the IEEE/CVF Conference on Computer
Vision and Pattern Recognition (CVPR)},
year={2026}
}