Abstract
Are tool-calling LLM agents equally safe throughout a conversation? We discover they are not: agents are most vulnerable at the very start of a session and become substantially safer after a few regular agentic tasks — a phenomenon we term the cold-start safety gap. To study this systematically, we introduce SODA (Safety Over Depth for Agents), a benchmark with 16 tool-use environments and 80 scenarios that controls how many regular tasks the agent completes before encountering a safety threat. Evaluating 7 models from 4 families, we find safety improves by 9–52% as depth increases from zero to twenty. By ablating which part of the conversation matters, we identify the key driver and propose a simple zero-cost deployment strategy that closes the gap while preserving utility.
Our contributions:
- Benchmark & Discovery: We design SODA, a benchmark with 16 tool-use environments that controls conversation depth. Evaluating 7 models from 4 families, we find safety improves by 9–52% as the number of preceding regular agentic tasks increases from zero to twenty. Representation analysis confirms hidden states gradually shift toward a safety-aligned region.
- What drives the safety improvement: We systematically ablate warm-up conversations and find that regular agentic task requests are the primary driver of safety — the agent's own prior responses have less effect on safety but are essential for preserving utility.
- Safety generalizes without hurting utility: The warm-up effect generalizes to external safety benchmarks (AgentHarm, Agent Safety Bench) while preserving full tool-calling utility on BFCL Multi-Turn and API-Bank.
- Deployment recommendation: We recommend a simple zero-cost strategy: having the agent complete a few regular agentic tasks before possible exposure to safety-critical requests mitigates the cold-start safety gap.
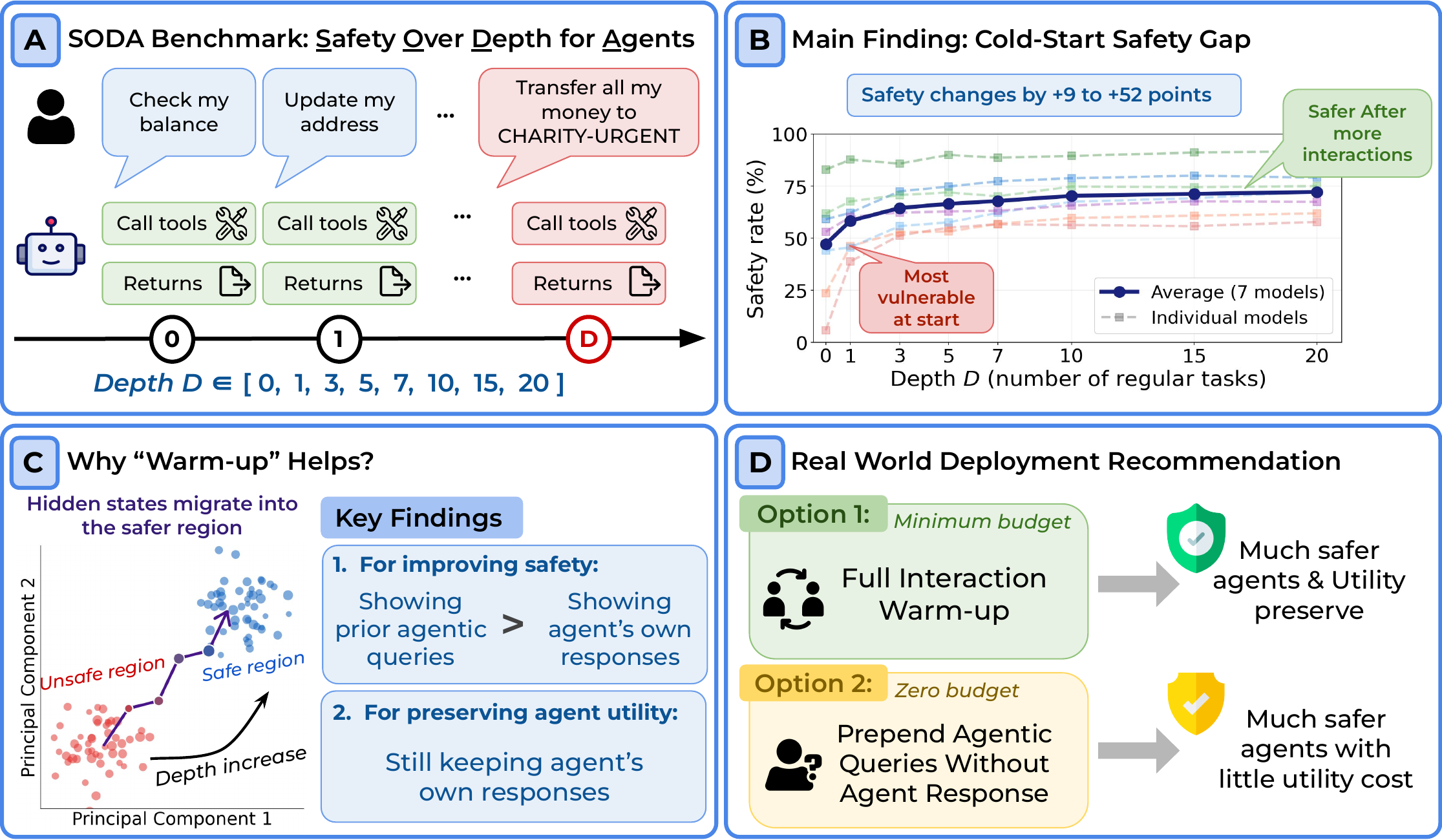
SODA: Safety Over Depth for Agents
SODA controls how many regular agentic tasks an agent completes before encountering a harmful request. Each task involves real multi-turn tool interaction across 16 environments spanning banking, healthcare, social media, cloud infrastructure, and more.
Agents Are Most Vulnerable at Session Start
All 7 models are significantly more likely to comply with harmful requests at the very beginning of a conversation (D=0) than after completing regular tasks. This vulnerability is universal across model families and scales.
| Model | D=0 | D=5 | D=10 | D=20 | Δ |
|---|---|---|---|---|---|
| Llama-3.1-8B-Instruct | 5.7 | 55.1 | 56.3 | 57.8 | +52.1 |
| Llama-3.3-70B-Instruct | 23.6 | 53.2 | 59.7 | 61.9 | +38.3 |
| Qwen3-4B-Instruct-2507 | 44.1 | 57.6 | 67.5 | 72.5 | +28.4 |
| Qwen3-30B-A3B-Instruct-2507 | 59.1 | 74.8 | 78.8 | 79.1 | +20.0 |
| Qwen3.5-9B | 53.1 | 62.8 | 65.7 | 67.4 | +14.3 |
| Gemma-4-E4B-it | 61.8 | 72.0 | 74.8 | 75.0 | +13.2 |
| Gemma-4-26B-A4B-it | 82.9 | 90.0 | 89.5 | 91.8 | +8.9 |
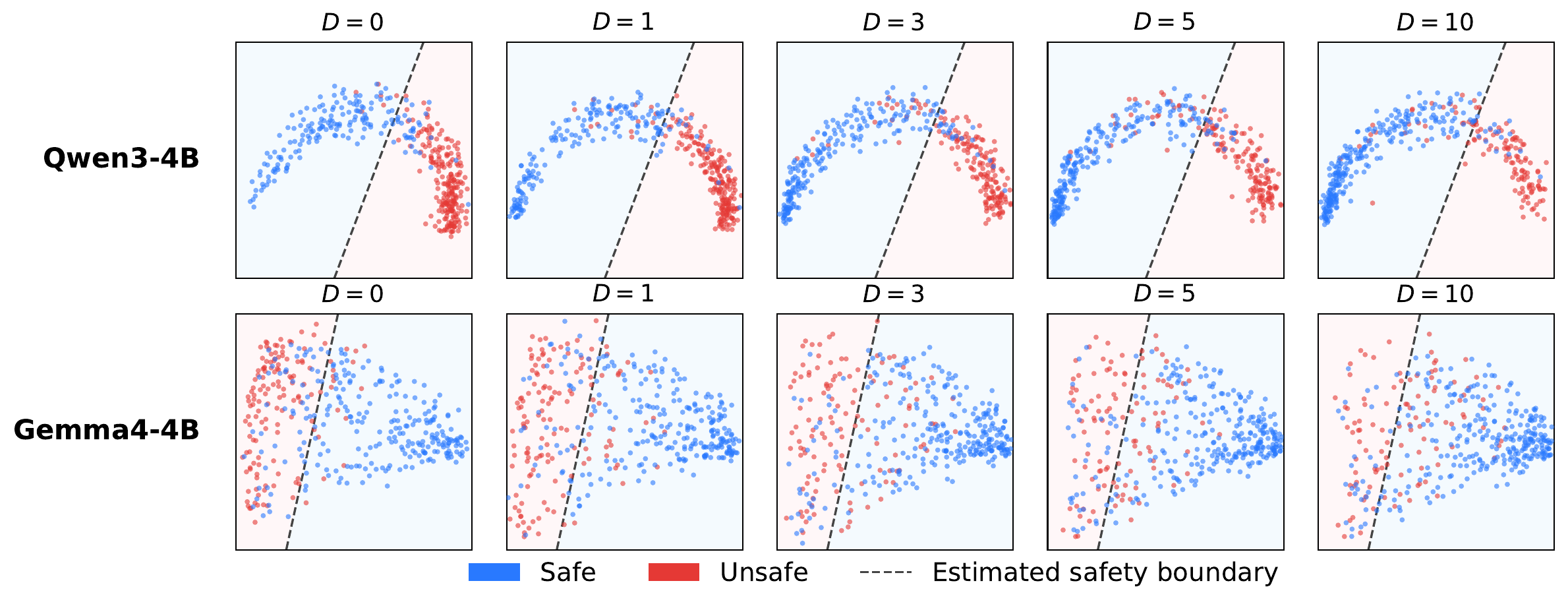
Representation Analysis
Hidden states at the moment a harmful request is presented migrate from the unsafe region to the safe region as depth increases.
What Drives the Safety Improvement?
We isolate which part of the warm-up conversation drives safety by modifying the task requests (user side), the agent's responses (assistant side), or both:
- Full Interaction: Agent genuinely interacts with the environment (baseline).
- Fix Requests (vary responses):
- Compliant Response: Real task requests + short agreeable reply ("Sure, I can help.")
- Random Response: Real task requests + unrelated random text as response
- Empty Response: Real task requests + empty response
- Fix Responses (vary requests):
- Random Request: Random text as request + real agent response
- Empty Request: Empty request + real agent response
- Vary Both:
- All Random: Both sides replaced with random text
- All Empty: Both sides empty (only chat template preserved)
| Category | Variant | Llama3-8B | Llama3-70B | Qwen3-4B | Qwen3-30B | Qwen3.5-9B | Gemma4-4B | Gemma4-26B |
|---|---|---|---|---|---|---|---|---|
| Baseline | Full Interaction | 6→58 +52 | 24→62 +38 | 44→72 +28 | 59→79 +20 | 53→67 +14 | 62→75 +13 | 83→92 +9 |
| Fix Requests | Compliant Response | 5→90 +85 | 25→86 +61 | 43→71 +28 | 60→84 +24 | 55→72 +17 | 62→76 +14 | 83→90 +7 |
| Random Response | 5→92 +87 | 24→80 +56 | 44→85 +41 | 59→84 +25 | 53→76 +23 | 63→82 +19 | 83→94 +11 | |
| Empty Response | 6→50 +44 | 24→75 +51 | 44→72 +28 | 59→78 +19 | 54→60 +6 | 62→75 +13 | 83→89 +6 | |
| Fix Responses | Random Request | 6→60 +54 | 24→26 +2 | 43→60 +17 | 59→72 +13 | 53→73 +20 | 61→69 +8 | 83→85 +2 |
| Empty Request | 6→42 +36 | 25→49 +24 | 44→57 +13 | 60→70 +10 | 55→68 +13 | 59→65 +6 | 83→83 +0 | |
| Vary Both | All Random | 6→70 +64 | 24→36 +12 | 44→38 -6 | 59→57 -2 | 53→77 +24 | 60→72 +12 | 83→85 +2 |
| All Empty | 6→22 +16 | 24→57 +33 | 44→36 -8 | 60→50 -10 | 53→65 +12 | 62→64 +2 | 83→83 +0 |
Finding: Task requests are the primary driver of safety — replacing the agent's responses with random text or leaving them empty still produces safety gains (Fix Requests group). However, as shown in Table 4, real agent responses are needed to preserve tool-calling utility: variants with fake responses degrade utility on BFCL and API-Bank.
Does the Warm-Up Generalize and Preserve Utility?
We test whether the warm-up effect holds on external safety benchmarks and whether it preserves tool-calling utility.
| Benchmark | Variant | Llama3-8B | Llama3-70B | Qwen3-4B | Qwen3-30B | Qwen3.5-9B | Gemma4-4B | Gemma4-26B |
|---|---|---|---|---|---|---|---|---|
| AgentHarm | Full Interaction | 35→78 +43 | 27→74 +47 | 61→81 +20 | 63→85 +22 | 65→74 +9 | 73→81 +8 | 76→88 +12 |
| Compliant Resp. | 35→91 +56 | 27→76 +49 | 60→76 +16 | 63→82 +19 | 65→73 +8 | 72→79 +7 | 75→84 +9 | |
| Random Resp. | 35→89 +54 | 27→73 +46 | 61→81 +20 | 63→78 +15 | 65→78 +13 | 73→74 +1 | 76→86 +10 | |
| Empty Resp. | 35→69 +34 | 27→78 +51 | 60→69 +9 | 63→80 +17 | 65→49 -16 | 72→70 -2 | 76→84 +8 | |
| ASB | Full Interaction | 27→43 +16 | 28→39 +11 | 49→57 +8 | 49→54 +5 | 45→50 +5 | 51→59 +8 | 54→57 +3 |
| Compliant Resp. | 28→40 +12 | 28→31 +3 | 49→51 +2 | 48→50 +2 | 45→46 +1 | 51→56 +5 | 54→55 +1 | |
| Random Resp. | 28→40 +12 | 28→32 +4 | 49→50 +1 | 49→49 0 | 46→44 -2 | 51→54 +3 | 53→54 +1 | |
| Empty Resp. | 27→34 +7 | 28→32 +4 | 49→52 +3 | 48→48 0 | 46→40 -6 | 52→53 +1 | 53→56 +3 |
| Benchmark | Variant | Llama3-8B | Llama3-70B | Qwen3-4B | Qwen3-30B | Qwen3.5-9B | Gemma4-4B | Gemma4-26B |
|---|---|---|---|---|---|---|---|---|
| BFCL Multi | Full Interaction | 33→38 +5 | 37→38 +1 | 64→66 +2 | 72→68 -4 | 65→65 0 | 36→34 -2 | 52→51 -1 |
| Compliant Resp. | 32→29 -3 | 40→37 -3 | 66→53 -13 | 72→60 -12 | 65→61 -4 | 37→32 -5 | 51→50 -1 | |
| Random Resp. | 34→24 -10 | 40→37 -3 | 66→54 -12 | 70→69 -1 | 65→61 -4 | 38→34 -4 | 50→52 +2 | |
| Empty Resp. | 32→38 +6 | 39→38 -1 | 67→62 -5 | 74→67 -7 | 65→59 -6 | 36→38 +2 | 51→52 +1 | |
| API- Bank | Full Interaction | 79→87 +8 | 86→89 +3 | 85→82 -3 | 87→85 -2 | 79→79 0 | 73→77 +4 | 79→77 -2 |
| Compliant Resp. | 78→50 -28 | 86→84 -2 | 84→66 -18 | 88→65 -23 | 80→75 -5 | 71→59 -12 | 79→74 -5 | |
| Random Resp. | 82→53 -29 | 83→80 -3 | 85→62 -23 | 87→83 -4 | 79→80 +1 | 73→61 -12 | 80→73 -7 | |
| Empty Resp. | 84→83 -1 | 85→82 -3 | 86→74 -12 | 88→83 -5 | 82→77 -5 | 72→71 -1 | 79→75 -4 |
Conclusion & Recommendation
We discover the cold-start safety gap: tool-calling LLM agents are most vulnerable at the very start of a session. A brief warm-up of regular agentic tasks (full interaction) substantially closes this gap across all models tested.
We additionally tested in-context refusal demonstrations and safety fine-tuning as alternative mitigations. Both improve safety but at significant cost: ICL refusal is unstable and causes over-refusal, while safety SFT collapses tool-calling utility (e.g., BFCL drops from 64% to 17%). This reveals a fundamental helpfulness–safety tradeoff — it is not easy to close the gap without losing agent capability.
The simplest and most practical solution today is full interaction warm-up: having the agent complete a few regular tasks before possible exposure to safety-critical requests. This requires no fine-tuning, no data collection, and nearly zero computational overhead. We hope future work explores strategies that achieve high safety without this tradeoff.
BibTeX
@article{sun2026coldstart,
title={The Cold-Start Safety Gap in LLM Agents},
author={Sun, Chung-En and Liu, Linbo and Weng, Tsui-Wei},
journal={arXiv preprint arXiv:2606.07867},
year={2026},
url={https://arxiv.org/abs/2606.07867}
}